
The Chunk Browser provides a means for you to observe the extracted chunks from the source data, giving you an insight into the output from the extraction process and enabling you to undertake subsequent actions like editing and rectifying the chunks. This not only allows you to view and verify the extracted chunks but also allows you to edit the chunks enabling you to work with answers in a way that best serves your specific goals and requirements.
The chunks browser displays chunks from all the content sources used to ingest data into the SearchAssist application.
Go to the Chunks page under the Indices tab to view the chunks extracted from content.
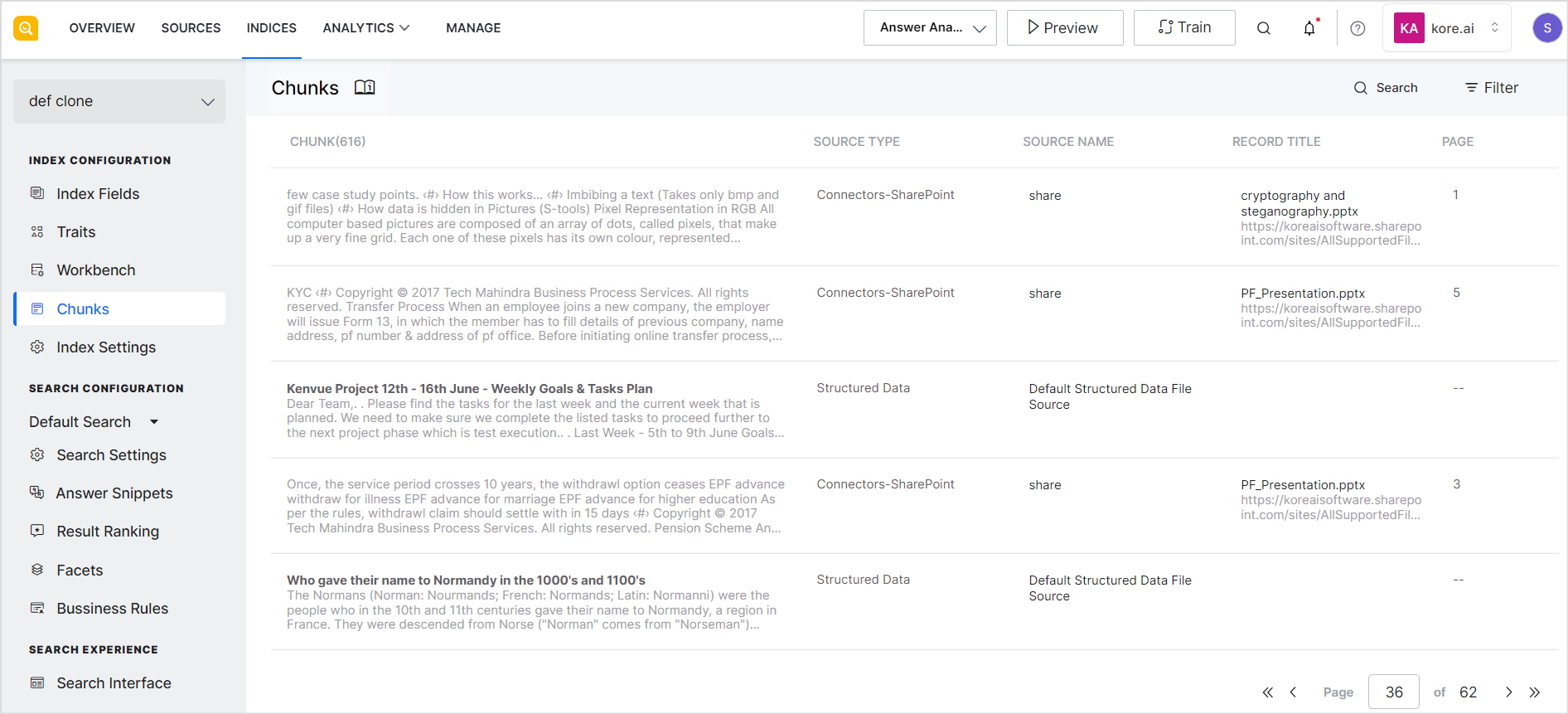 Every chunk record shows the chunk content, source of the chunk, title of the source, record title, and page number, if applicable.
Every chunk record shows the chunk content, source of the chunk, title of the source, record title, and page number, if applicable.
To view or edit a specific chunk, click the record. This will open the Chunk Viewer where you can see the details of the chunk. 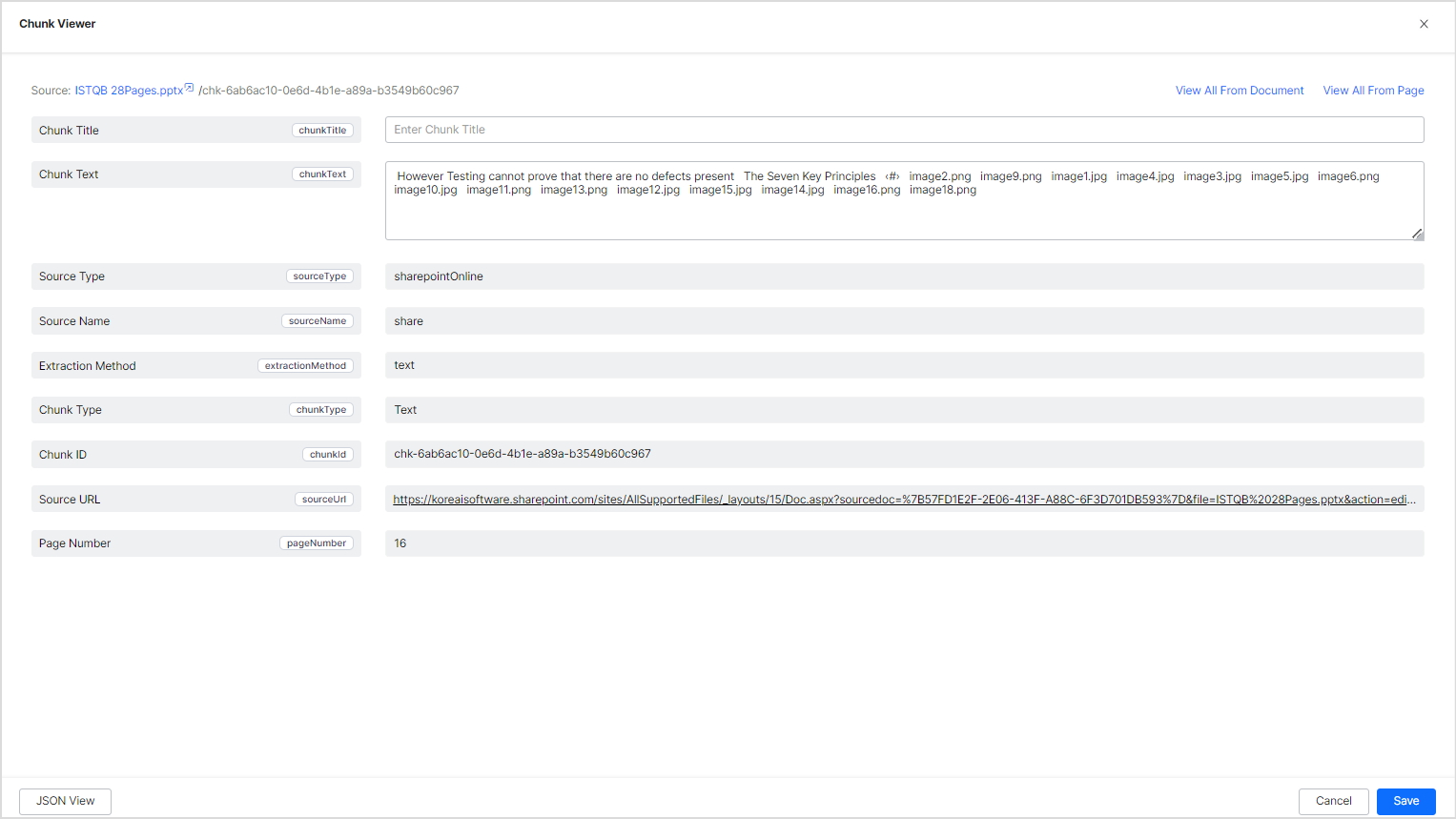
View Chunk Details
To view or edit a specific chunk, click the record. This will open the Chunk Viewer where you can see the details of the chunk.
Chunk Title: Title given to the chunk
Chunk Text: Content of the chunk
Source Type: The source type of the content like web pages, files, connectors, FAQs, or structured data.
Source Name: Name of the source from where the chunk is extracted
Extraction Method: Type of extraction model for the chunk. SearchAssist supports the following two types of extraction methods:
- Extractive– The extractive model refers to a rule-based model that follows predefined rules or patterns to identify and extract specific segments or chunks of information. The rules are typically set to recognize certain patterns or structures within the text, allowing the model to pinpoint and retrieve chunks of information based on the defined criteria.
- Text– Text Extraction Model combines techniques from natural language processing (NLP) and machine learning. Tokenization is employed to break the text into units, and the model is trained to identify and extract relevant chunks based on specified criteria.
Chunk Type: This defines the type of data in the chunk. It can take the following values: paragraph, list, image, or table.
Chunk ID: Unique identifier given to the chunk
Source URL: URL of the source from where the chunk is extracted, if applicable.
Page Number: Page number in the source file from where the chunk is extracted, if applicable.
You can edit the chunk text and the chunk title to enhance the chunk for your specific needs. This page also provides you with the following two quick filters. 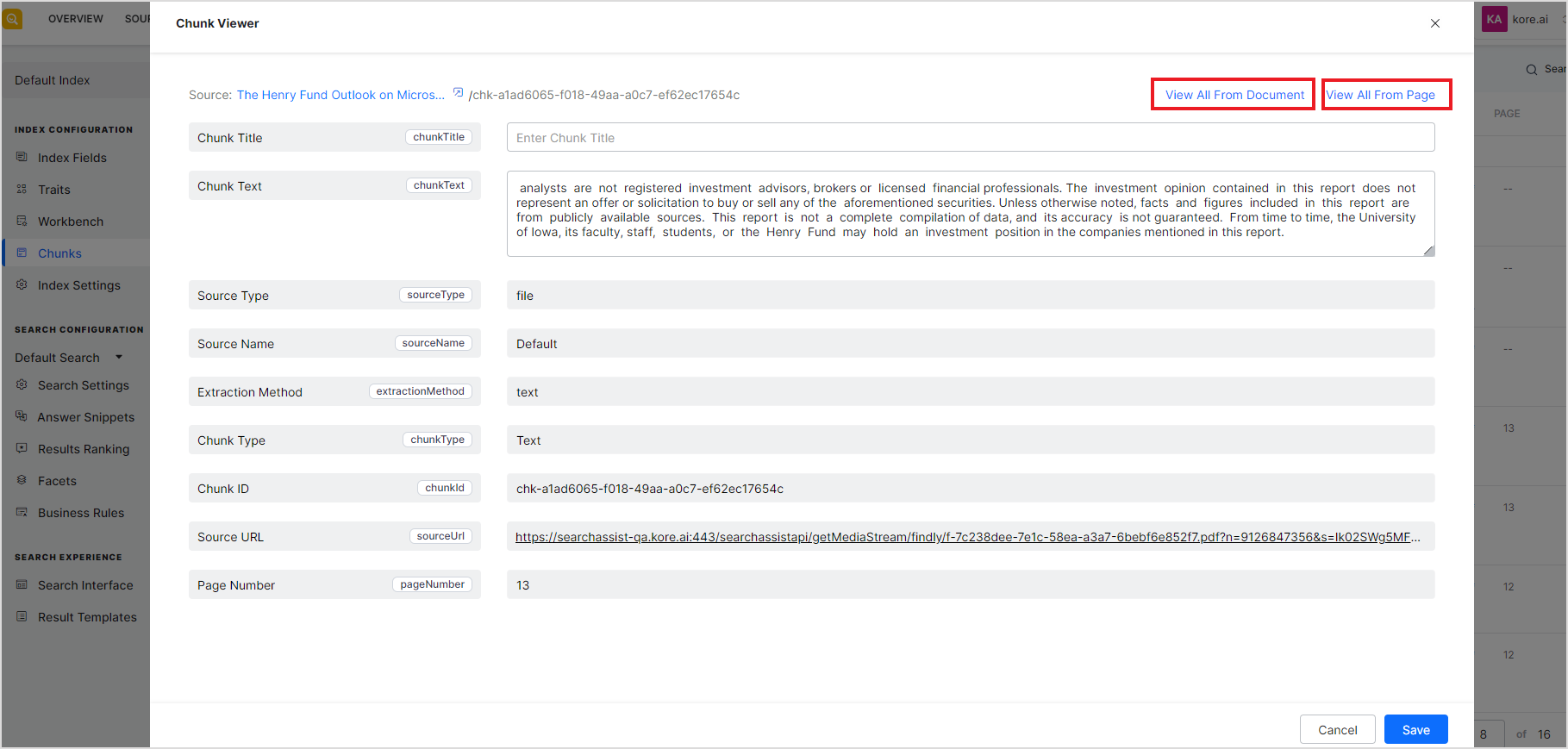
View All From Document: This lists all the chunks extracted from the same source.
View All From Page: This displays all the chunks from a specific page in the document. Currently, this is supported only for PDF files.
You can also view the contents of the chunk in JSON format. To do so, click on the JSON view button at the bottom of the page. 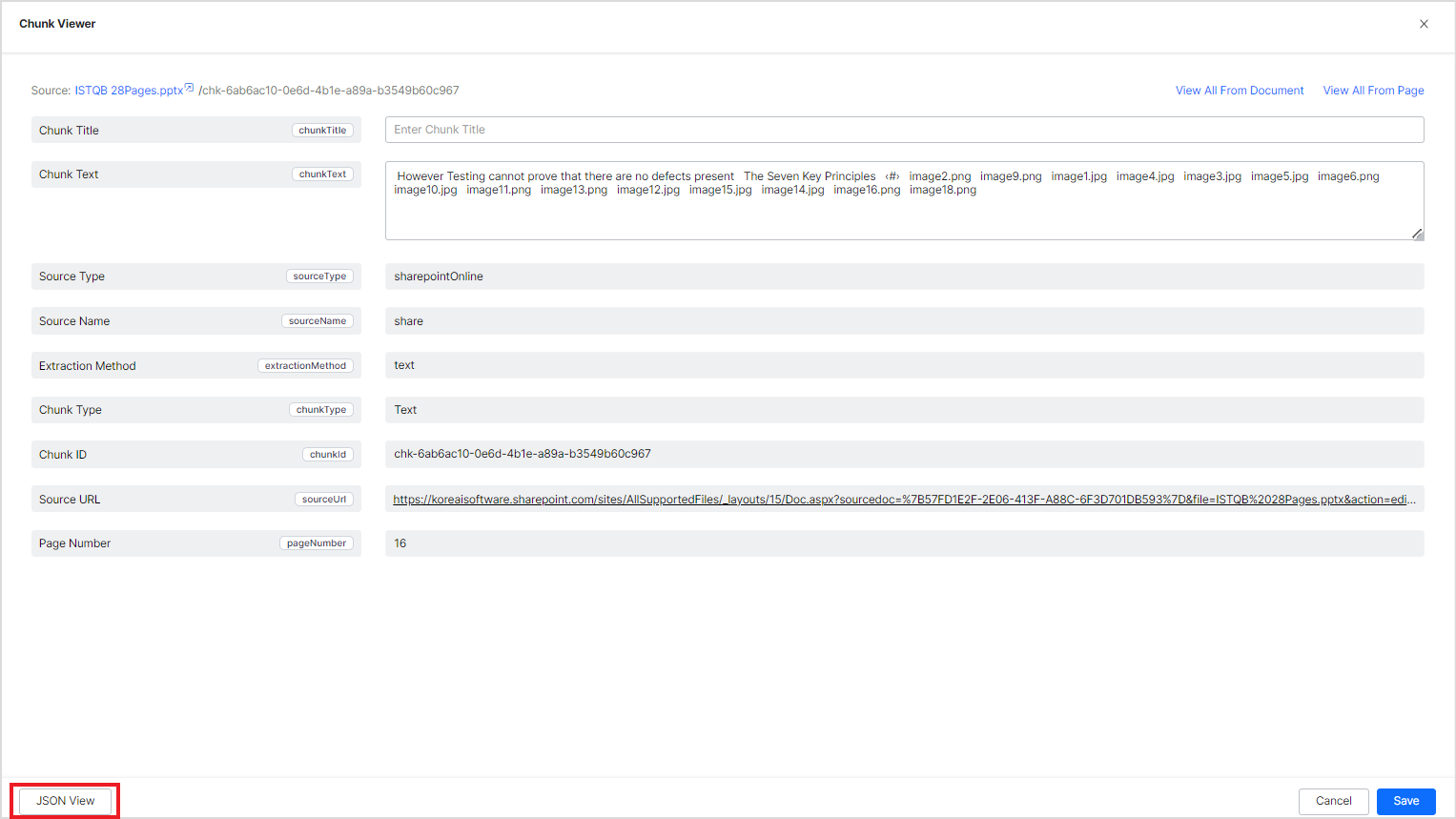
JSON view lists all the details of a given chunk as extracted by the application. It has additional fields as compared to the Summary view. 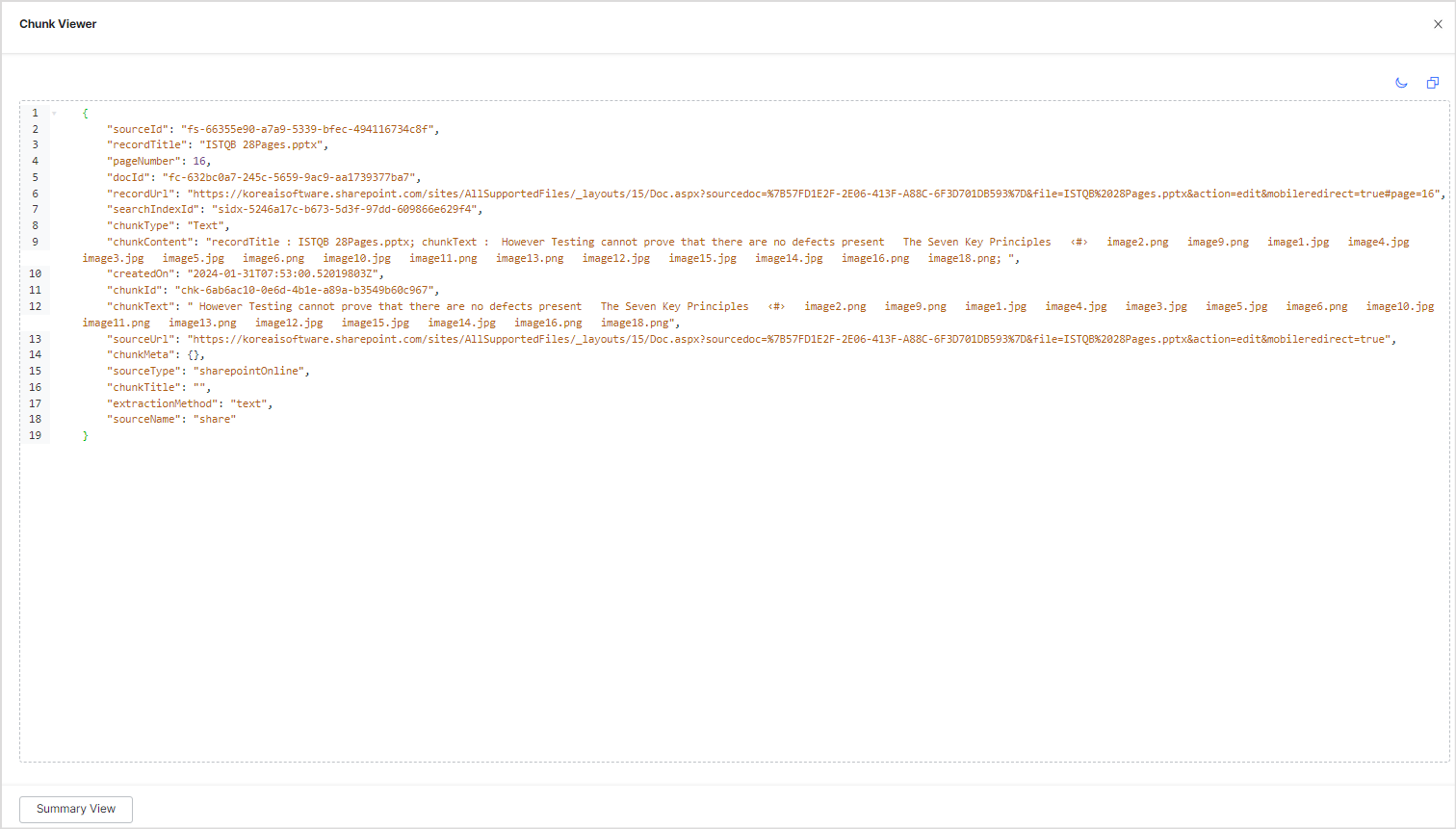
Searching for Chunks
The chunk browser also allows you to search for specific chunks. Use the search bar at the top right corner of the page to search chunks based on any of the fields of the chunks like title, source, etc. 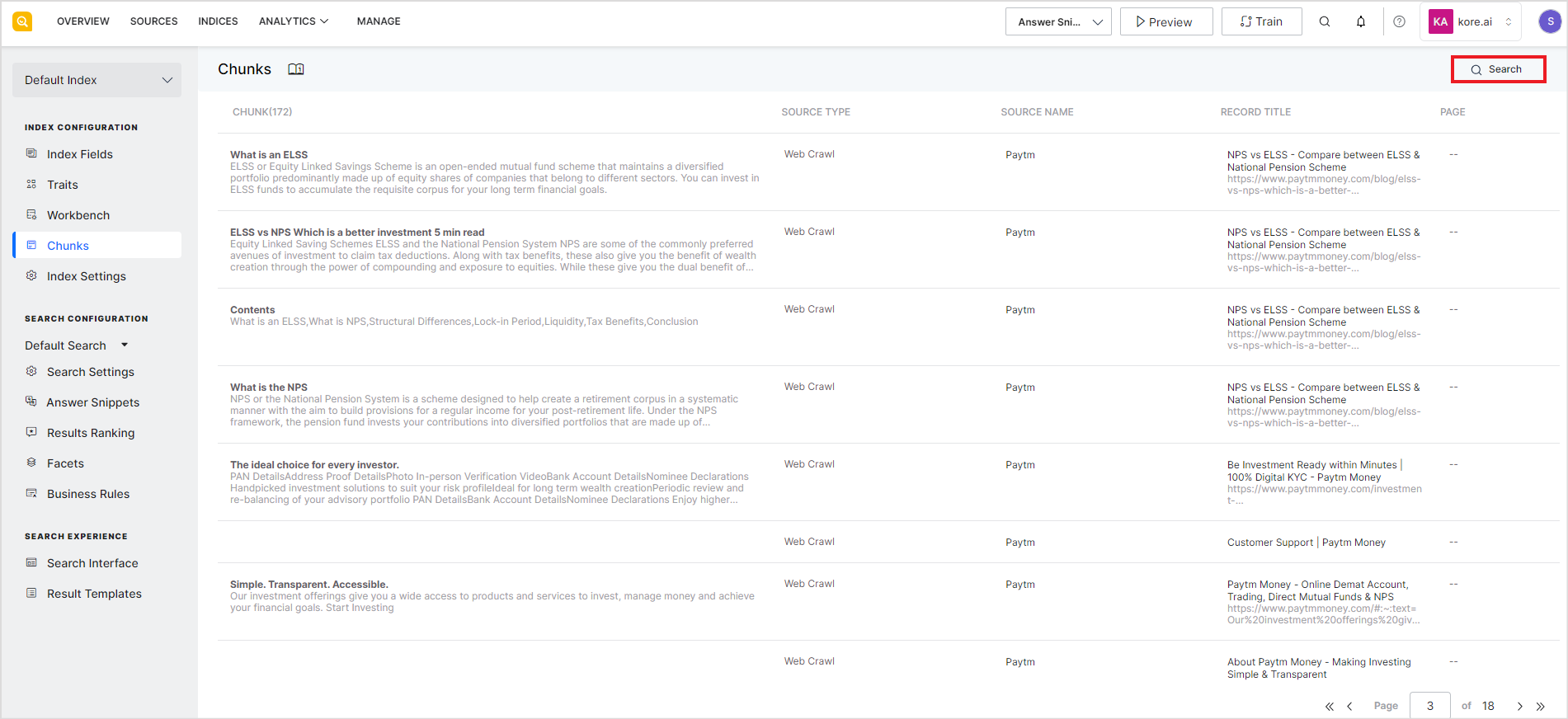
Filtering Chunks
SearchAssist provides filter options to help you find specific chunks. These filters enable you to narrow down your search based on various properties of the chunks like source type, name, extraction type, content, etc.
To filter chunks, click the Filter button on the top right corner of the page.
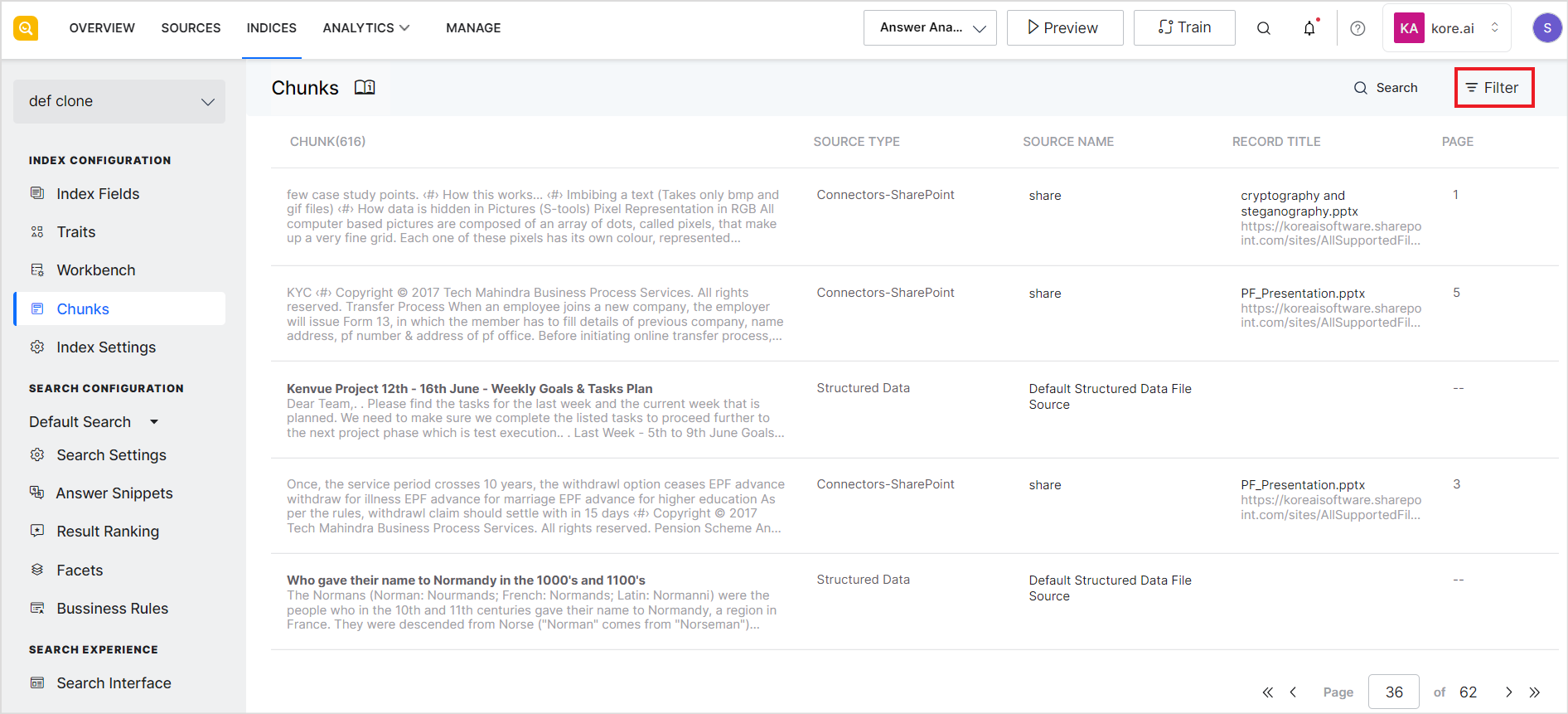
It lists the filter options as shown below.
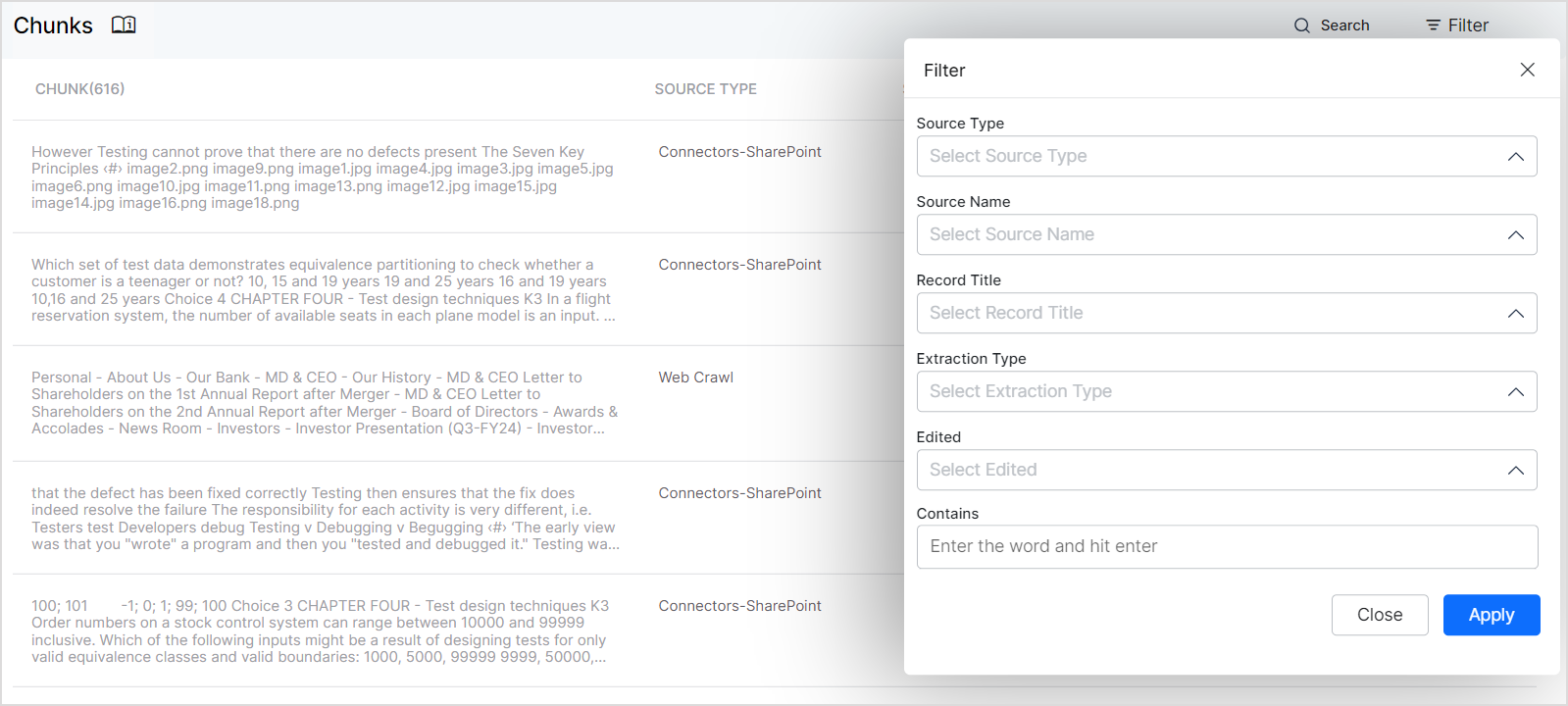
Available Filters
Source Type:
Filter chunks based on the type of data source, such as web pages, files, connectors, etc. Selecting a specific source type allows you to focus your search on chunks derived from that particular type of source.
Source Name:
Filter chunks based on the source name. This option enables you to view chunks generated from all content under a selected source.
Record Title:
Filter chunks based on the title of the record or resource. Use this filter to narrow down your search to chunks generated from a specific resource.
Extraction Type:
Filter chunks based on the extraction method used. This filter allows you to view chunks generated using a specific extraction type, such as text-based chunk generation (used for Generative Answers).
Edited:
Filter chunks based on whether they have been manually edited or not. Use this option to view only the chunks that have been edited or those that remain unedited.
Contains:
Filter chunks based on whether they contain a given word or phrase. This filter is useful for finding chunks that include the given set of keywords or phrases.