
What are Answers?
Answers are specific pieces of information extracted or generated by a search application in response to a user query.
Difference between Search Results and Answers
Search results usually present a list of documents, web pages, or content retrieved in response to a user query, ranked based on their relevance to the query. On the other hand, Answers aim to directly address user queries and provide an exact, precise piece of information as the response.
Types of Answers in SearchAssist
- Extractive Answers: Extractive answers involve selecting and presenting relevant chunks of text directly from the source documents that contain the answer to the user’s query. Extractive answers preserve the original wording and structure of the content
- Generative Answers: Generative answers involve using the retrieved chunks to generate answers to the query based on the understanding of the question and the relevant information in the source documents.
- Answers are usually paraphrased to reply to the exact user query.
- LLMs are used to generate answers from retrieved chunks.
Overview of Answer Generation Process
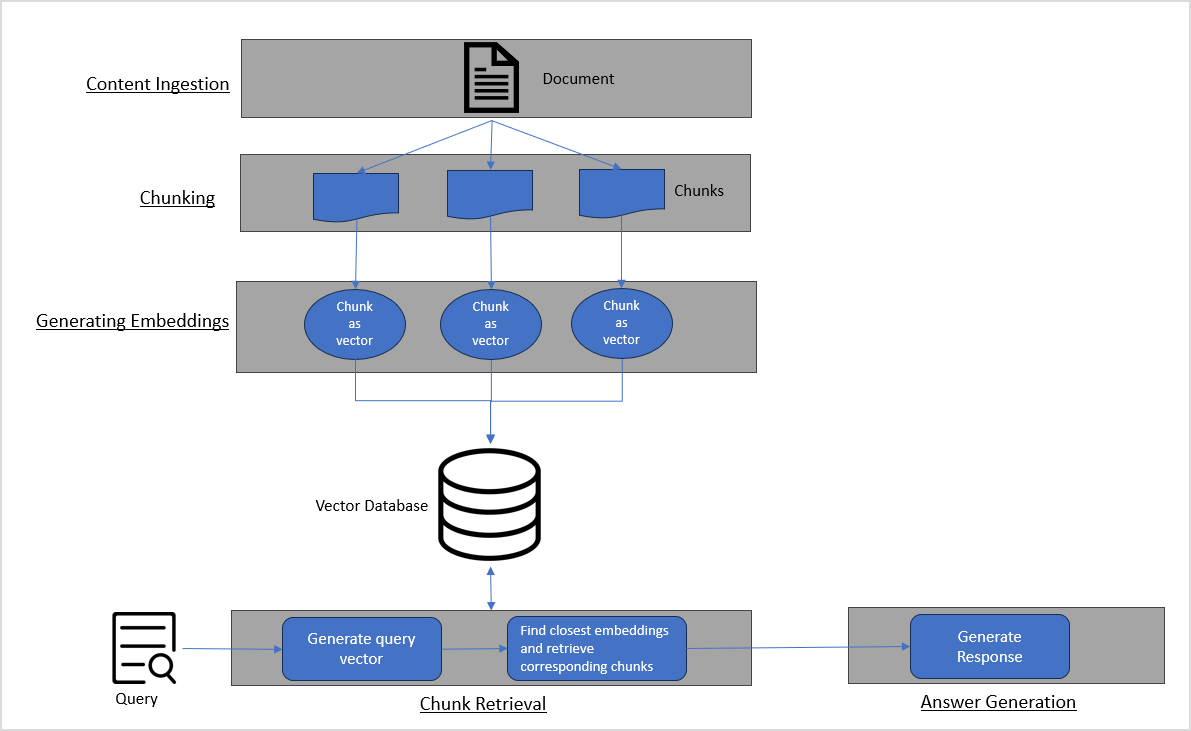
The answer-generation process mainly consists of the following steps:
- Content Ingestion: Involves processing of source documents that will be used for generating answers.
- Chunking: Involves breaking down the source documents into smaller, meaningful units called chunks.
- Generating Vector embeddings: Involves converting chunks into multi-dimensional vectors representing the chunks.
- Chunk Retrieval: Involves selecting the most relevant chunks of text from the vector space based on their similarity to the user query.
- Answer Generation: Involves generating a response to the user query based on the retrieved chunks.
Important terms related to Answers
- Chunks: Chunks refer to portions or segments of ingested data that are processed or evaluated as a single entity.
- Chunking: In the context of answers, Chunking is the process of segmenting large content units into smaller segments. SearchAssist uses different chunking strategies for Generative and Extractive Answers. So, when both types of Answers are enabled, two sets of chunks are created from the content and stored in the Answer Index.
- Chunking strategy refers to the rules used for chunk generation. Currently, SearchAssist uses the following two strategies for chunking.
- Text-based chunking: This technique is based on the concept of tokenization. A fixed number of consecutive tokens are identified as one chunk, the next set of tokens as the next chunk, and so on. SearchAssist uses this technique for Generative answers.
- Rule-based chunking: This technique uses the headers and content in a document to identify chunks. The header and the text between the header and the next header are treated as a chunk. SearchAssist uses this technique for Extractive answers.
- Embeddings: Generating Embeddings is the process of creating multi-dimensional vectors from the chunks. These embeddings are then stored in a vector database or vector store. There are different embedding models for generating embeddings. SearchAssist uses MPNet embeddings for English-only use cases, and LaBSE embeddings for multi-lingual use cases. The vector store used in both cases is ElasticSearch.
- Chunk retrieval: It is the process of retrieving the most relevant chunks corresponding to a user query. We support the following two techniques to retrieve chunks. You can experiment with both retrieval methods to find the one that provides optimum results for you.
- Vector retrieval: In this method, the idea is to find vectors that are more similar to the query vector. The chunks corresponding to the vectors most similar to the query vector are then used for generating answers.
- Hybrid retrieval: This method combines the keyword-based retrieval technique with the vector retrieval techniques, leveraging the strengths of both approaches.
- Retrieval Augmented Generation or RAG : This is a method that allows you to extract insights from fragmented, unstructured data and formulate responses based on the information. It involves retrieving both the content and context from a dataset and utilizing this knowledge to generate responses. This technique significantly enhances the precision and relevance of the generated answers.
- Tokens: Tokens refer to a group of characters. In computing terminology, a token is the smallest unit of data. Roughly, 1 token ~= 4 chars in English.
- Answer Index: Index refers to searchable content from which SearchAssist generates results. Answer Index is the searchable content from which Answers are generated. Similarly, Search Index is the searchable content from which Search results are generated.