
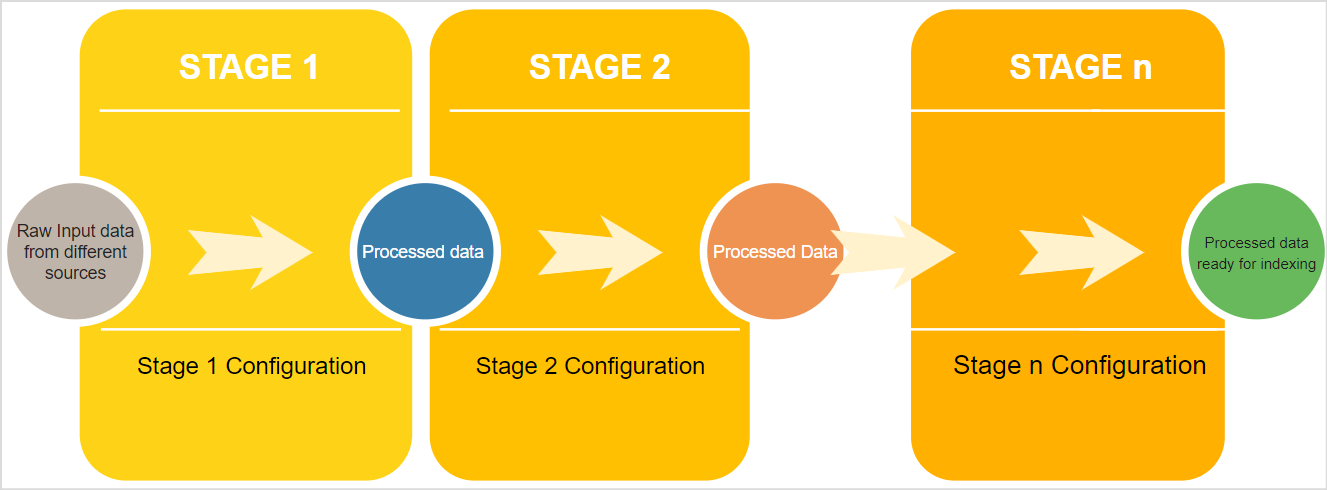
Workbench is a SearchAssist tool that converts content into objectively indexed documents. It processes the ingested content in a series of stages known as the Index Pipeline. Collectively, the Index pipeline converts the ingested content into a document ready for indexing. Each stage performs a specific set of data transformations before passing the content onto the next stage in the pipeline. The data transformations at each step can be customized as per your business needs using the configuration parameters for the stage. You can use the simulator to test the configuration at each step individually or the cumulative effect of the various stages. You can rearrange or sequence the stages in any preferred order as per your requirements. To summarize, the workbench operations can be represented as:
To configure the workbench and introduce Index Pipeline stages for content processing, go to the Workbench page under the Indices tab.
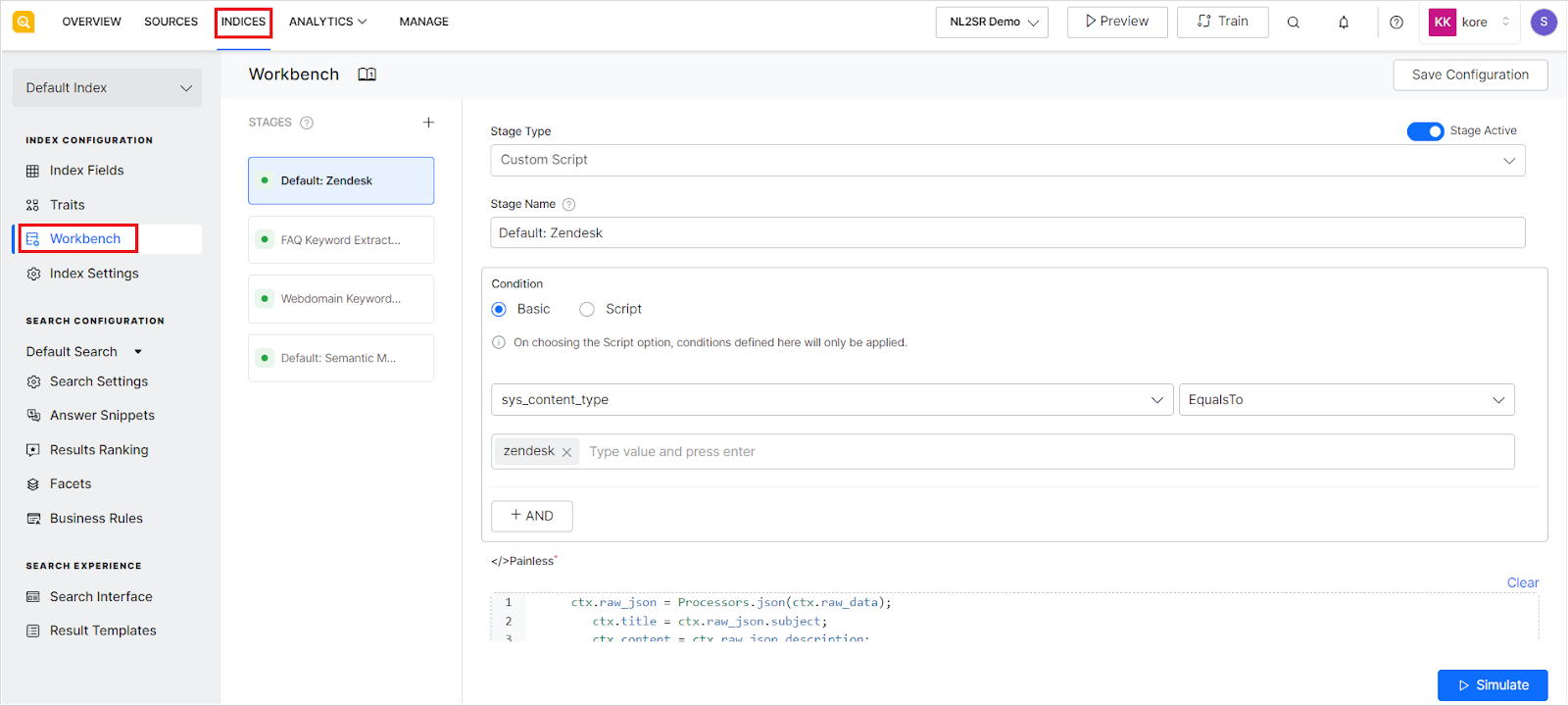
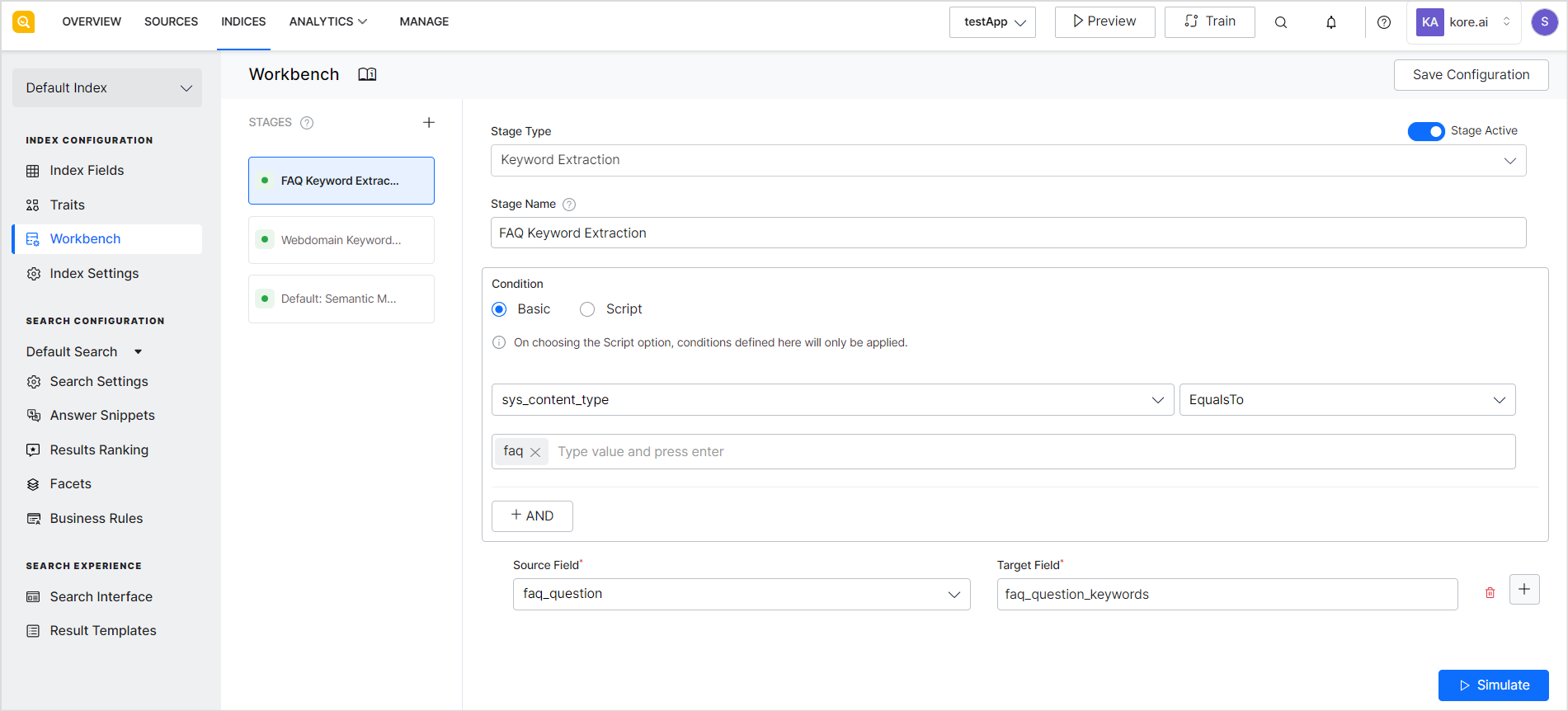
SearchAssist supports the following Index Pipeline stages.
- Field Mapping maps fields in an indexing pipeline document to a target field, sets values, copies values, removes fields, renames fields, and more.
- Entity Extraction uses NLP techniques to identify named entities from the source field. For example, finding dates or geographic locations from a document.
- Traits Extraction extracts specific attributes that search users might express in their conversations. When traits are extracted from the source documents, SearchAssist can find more relevant results for the users.
- Custom Script stage allows you to enter customized scripts to perform any operations on the fields like deleting or renaming fields.
- Keyword Extraction automatically detects and extracts important words stored in a field.
- Exclude Document stage drops all the documents that match the specified condition.
- Semantic Meaning is a technique to understand the meaning and interpretation of words, signs, and sentence structure. This stage currently supports web page-related sources only.
- Snippet Extration stage allows you to configure the answer snippets generation from the documents.
- Custom LLM prompt stage allows you to configure the prompts to be used for data enrichment using the third-party LLMs.
Each indexing stage has properties like stage type, stage name, and applicable conditions to choose the index fields that must be transformed and the change to be performed.
Adding a new stage to Workbench
By default, the following three Workbench stages are defined for every app:
- Keyword Extraction stage for FAQs
- Keyword Extraction stage for web pages
- Semantic meaning stage
To add a new stage, click the Add stage button or the + icon. Select the stage type you want to add from the drop-down menu. 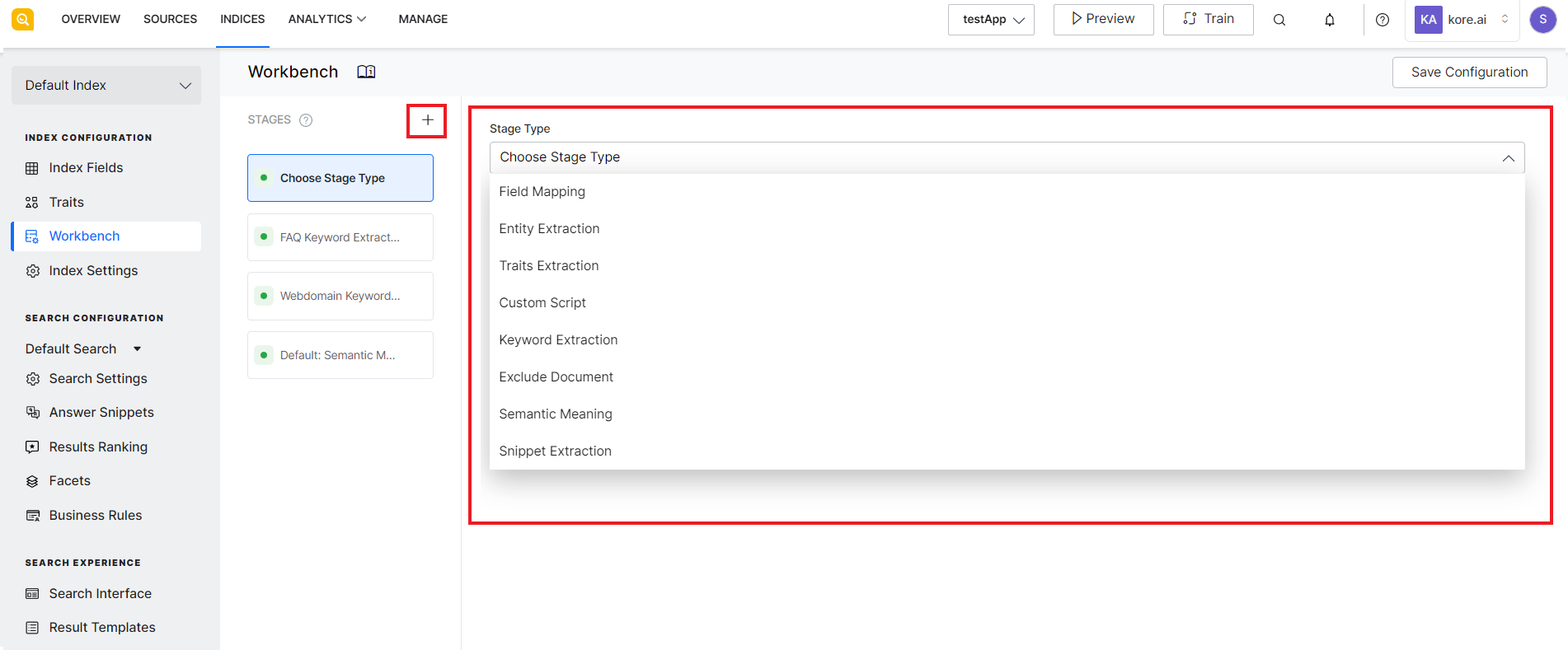
After selecting the Stage Type, set the related configuration parameters. You can find more information about the configuration parameters for each stage under the details of the corresponding stage. Click Save Configuration to save the changes made to the Workbench.
Ordering the Stages
You can rearrange the stages at any time as per the order in which you want the data to be processed. To do so, go to the stage name that you want to move in the left panel and use the draggable dots icon to move and place the stage as required. 
Activating or Deactivating a stage
To activate or deactivate a stage, go to the stage and use the toggle button on the top right corner of the page. 
The active stages are represented by a green icon in the left panel whereas the inactive stages are shown in grey.
Deleting a stage
To delete a stage from the Workbench, go to the stage in the left panel, click the cross icon after the name of the stage on the left, and save the Workbench configuration. 
Testing and Simulation
The Workbench comes with a built-in simulator that has an interactive preview of how the stage rules affect a document before it’s indexed. Click the Simulate button at any point to test the changes made to the source data due to the workbench stages. The simulation is performed on a sample set of documents. This can help you test the behavior of the Index Pipeline and fine-tune the output as per the requirements.
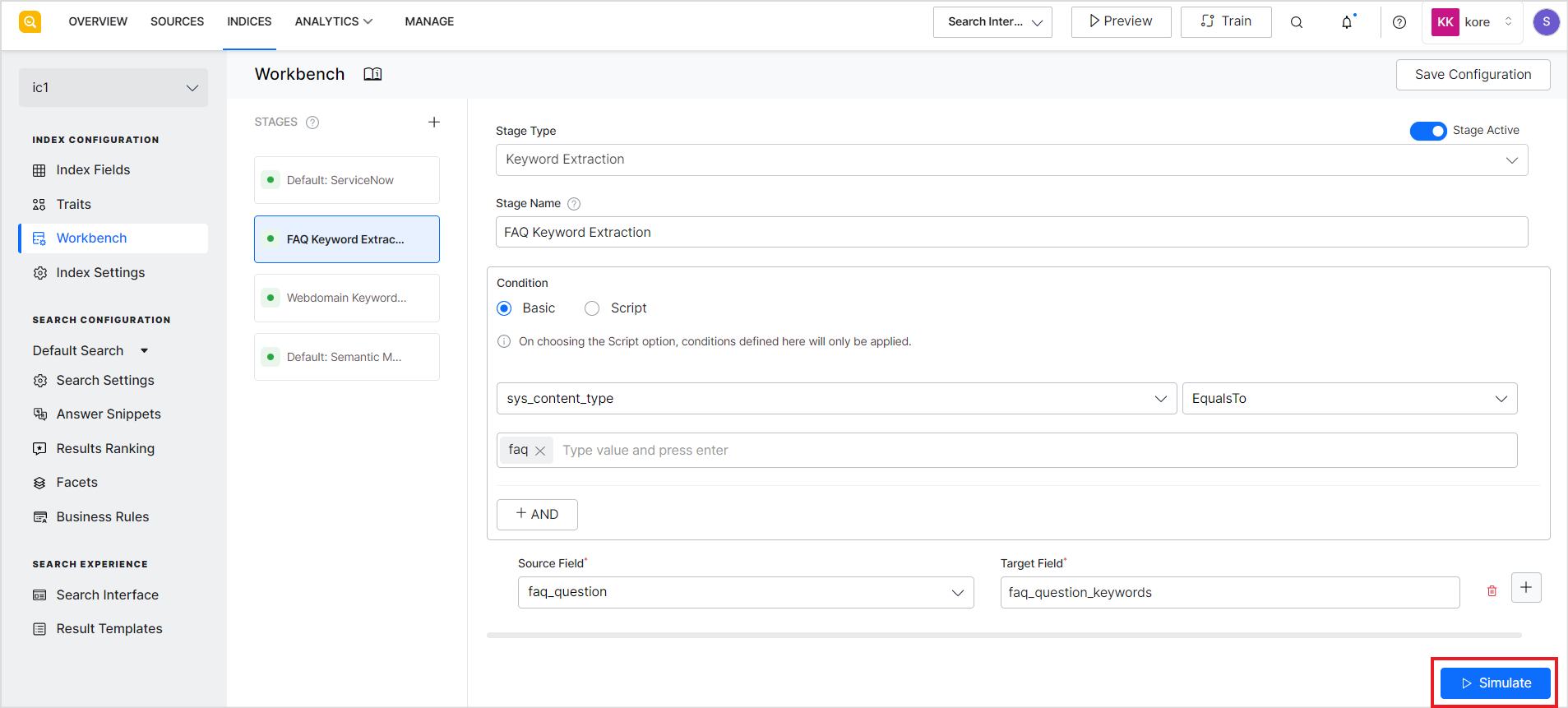
The simulator shows the changes made to the input data when processed through all the stages of the Workbench in the order in which they are listed. When you select Simulate option on a particular stage, the simulation happens as per the stages before that stage. You can also test individual stages of the pipeline by making the other stages inactive temporarily.
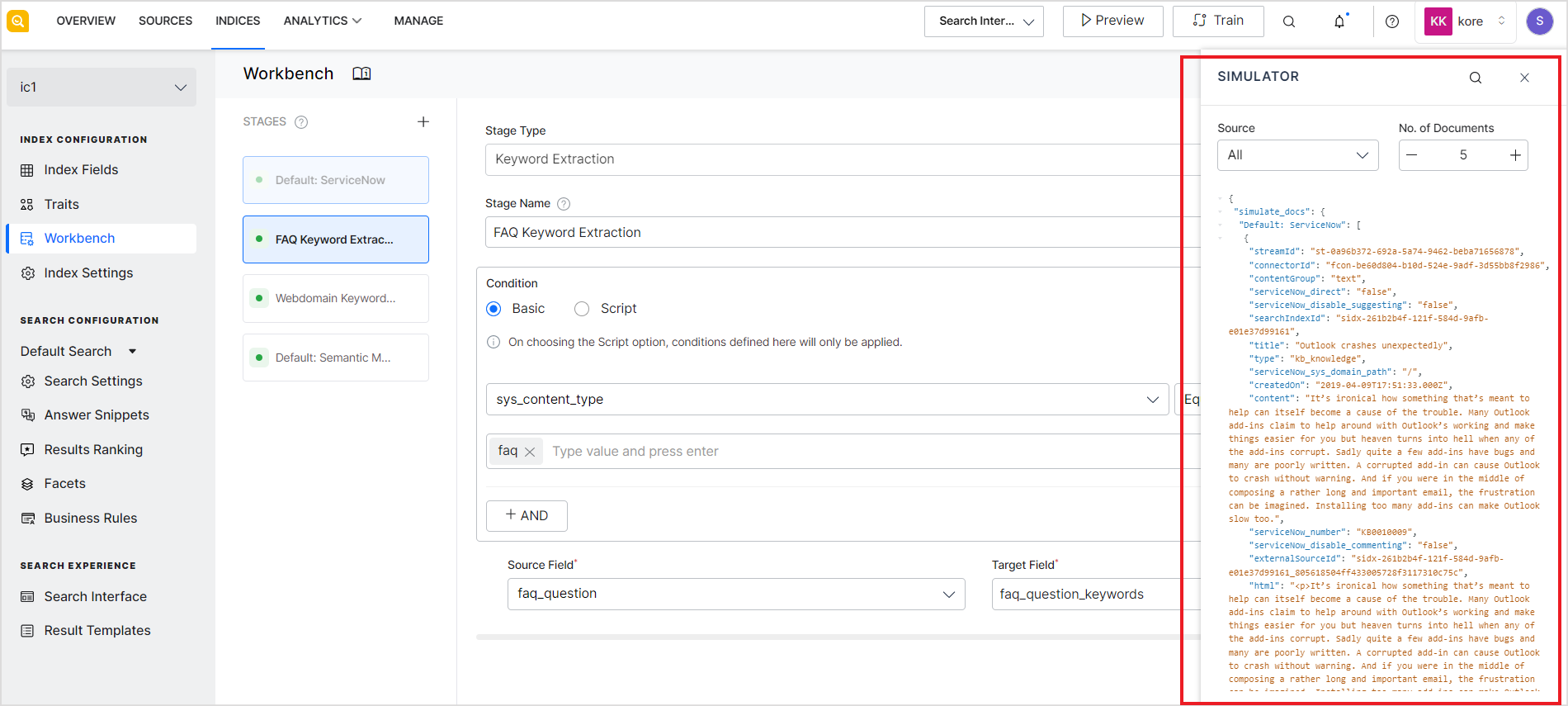
The simulator can display up to 20 documents or records. You can choose to see the output of the workbench stages on all the types of source data or only on a particular type of data like webpages, files, etc.