Overview
Painless is a simple, secure scripting language designed for performance and safety. Painless is seamlessly integrated with SearchAssist allowing you to use Painless to write custom scripts within the Workbench stages and implement custom tasks and preprocess data before it is indexed.
Syntax and Constructs
Painless is a custom scripting language by ElasticSearch. For more information on Painless, refer to the official documentation here. Painless script is built on top of Java, sharing the basic constructs with Java language. Refer to this for the specifications of those constructs.
Getting Started
Before you begin to write your first script, it is important to understand how content is indexed within SearchAssist. Any content ingested by the SearchAssist application is stored as a JSON object, and each object contains Index fields that represent a specific piece of data about the content. Some fields are common, while others vary according to the type and source of content. For example, when a web page is crawled, its title is stored in the field page_title, and the body is stored as page_body. The predefined fields for each content type are listed under the Index Fields page. Note that Index fields are a subset of the fields with which you can work in the Workbench. 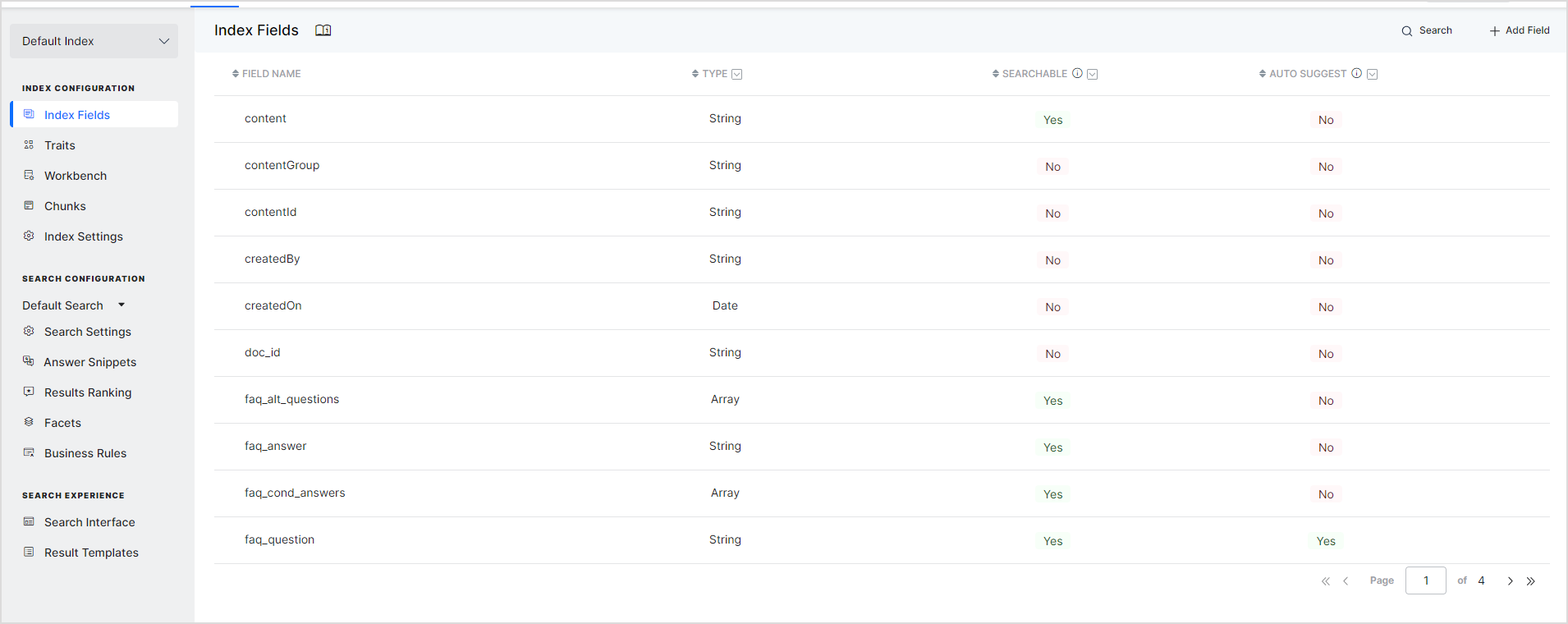
If there are any custom fields that you have created for structured data or during Workbench processing, you can use those as well in the scripts. You can view the list of available fields for processing in a stage using the Workbench Simulator.
Writing the Script
Painless scripts provide you a way to access and manipulate Index field values for a document as per your specific business requirements. You can use them to define conditions or outcomes in the Workbench Stages.
To facilitate access and updates to the information in the document, Painless introduces a variable ctx that allows access and interaction with the context object. This variable enables you to access and update the fields in the current document.
To access the values of any Index Fields in the current document, use ctx.<field-name>. For example, if you need to refer to the page URL, use
ctx.page_url
Similarly, you can also create new index fields. For example, the following script will create a new field ‘new_field’ that will have the same value as that of the pageTitle field of the document. >ctx.new_field = ctx.pageTitle;
Sample Implementation
Let’s create a sample script to count the total number of pages in a file and introduce a new field that stores this value.
File information already has an object, file_content_obj, that stores the pages of the file. To count the total number of pages, iterate over the object and increment the count till you find a null object. Finally, set the count to another field in the document.
int temp_total_pages = 0; if(ctx.file_content_obj != null){ for (def item: ctx.file_content_obj) { if (item!="") { temp_total_pages = temp_total_pages+1; } } } ctx.total_pages = temp_total_pages;
When to use scripts
While defining conditions in any of the Workbench Stages, you can use the scripts to identify the content on which a certain outcome should be applied. Go to the Script tab under Condition and write your script. Note that the script should evaluate to either true or false when it is used for defining conditions. 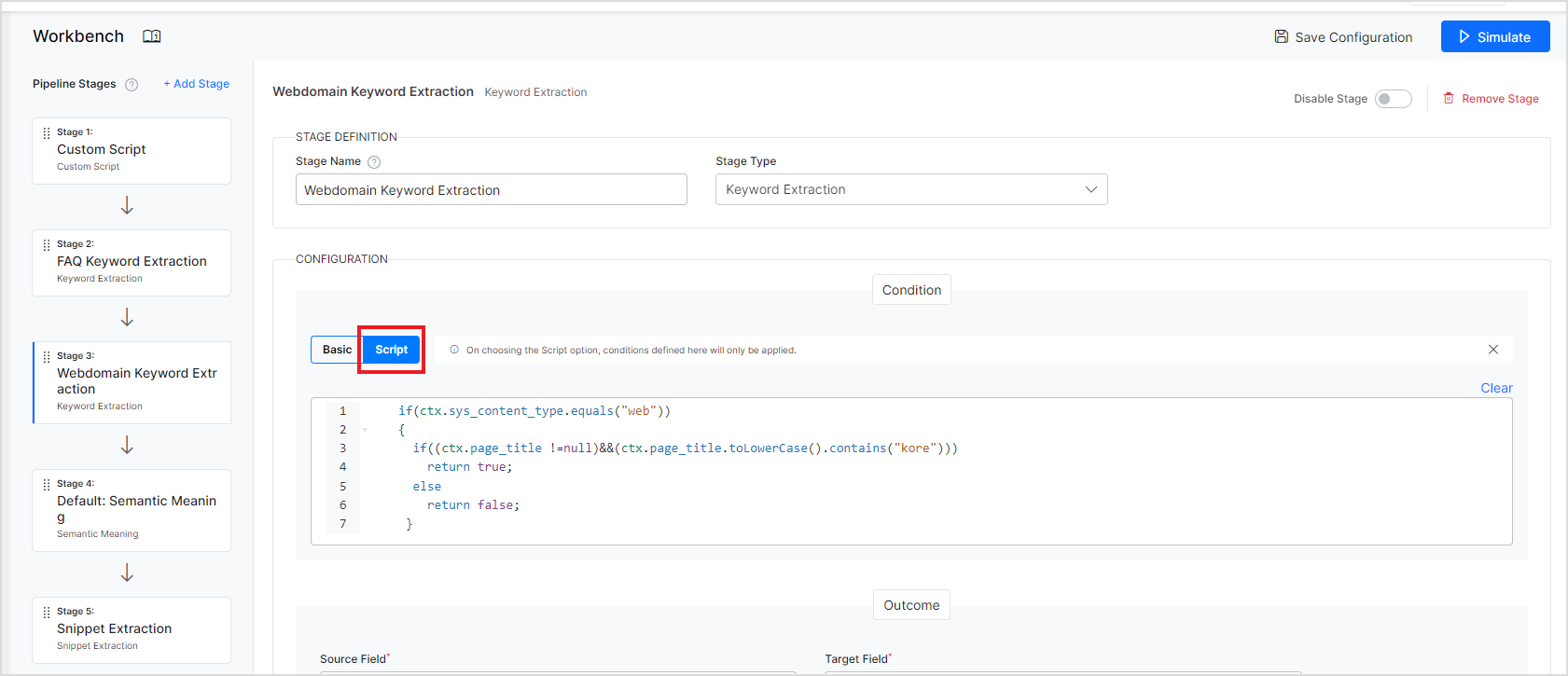
For example, to take action only on web page content when the title has a specific word ‘Kore’ in it, you can write a script as shown below.
if(ctx.sys_content_type.equals("web")) { if((ctx.page_title !=null)&&(ctx.page_title.toLowerCase().contains("kore"))) return true; else return false; }
Similarly, you can use a script to define the outcome in the Custom Script Stage of Workbench and specify the outcome or action to be taken on the content that meets the conditions. You can use the values of existing fields, update them, or create new fields while defining the outcome to achieve the desired results. 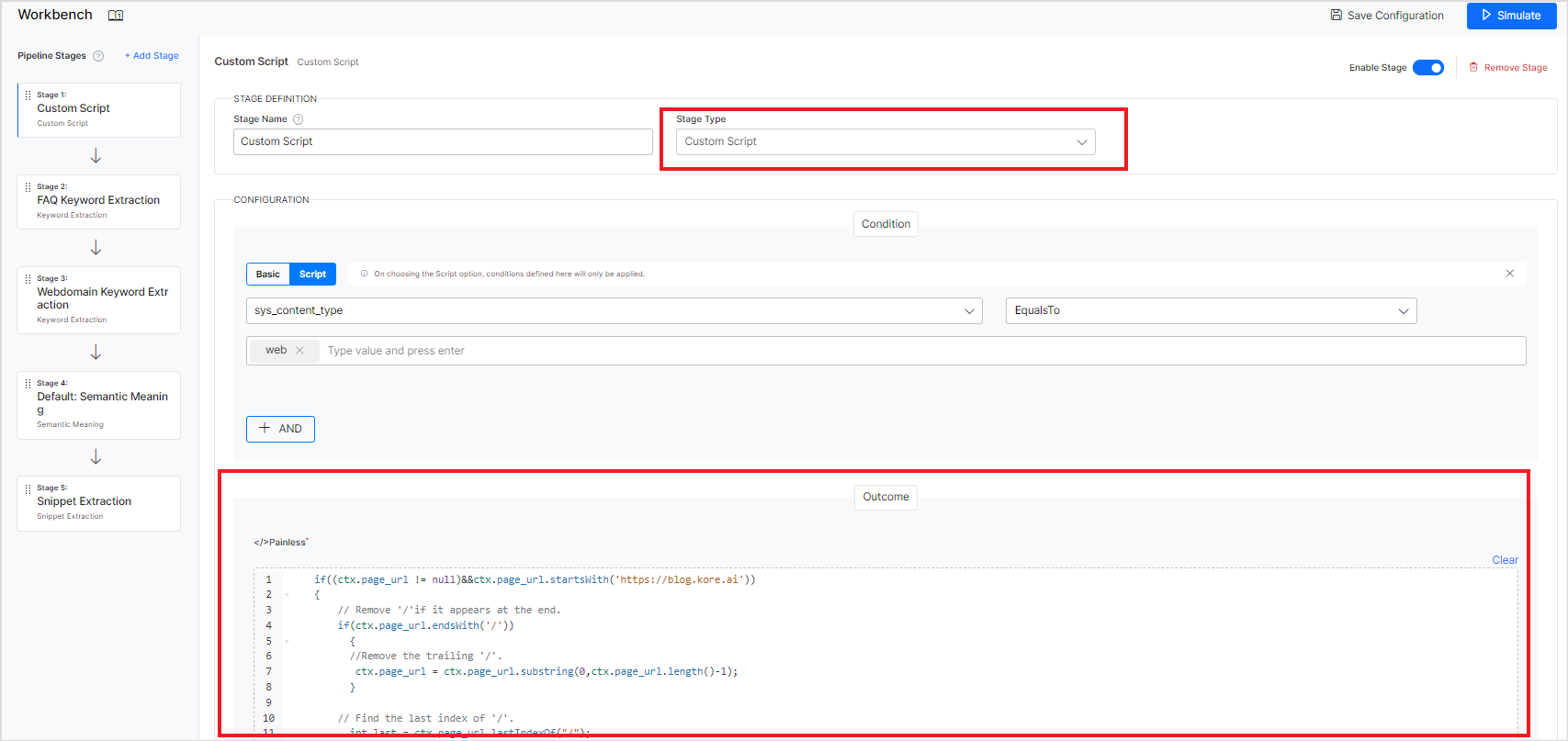
For example, if there is a need to extract a part of the URL and add it as a new field, you can use the following script. Like, if page_url = https://developer.kore.ai/docs/bots/bot-intelligence/interruption-handling-context-switching-intents/, new field should be set to ” interruption handling context switching intents”.
if(ctx.page_url.startsWith('https://developer.kore.ai')) { // Remove '/'if it appears at the end. if(ctx.page_url.endsWith('/')) { //Remove the trailing '/'. ctx.page_url = ctx.page_url.substring(0,ctx.page_url.length()-1); } // Find the last index of '/'. int last = ctx.page_url.lastIndexOf("/"); //Return all the words after the last '/' and replace '-'with spaces, if any. ctx.new_field = ctx.page_url.substring(last+1, ctx.page_url.length()).replace("-"," "); //Set the new field as page title, if it does not exist if(ctx.page_title == null) ctx.page_title = ctx.new_field; }
Testing and Debugging
Whenever a custom script is implemented, it is advisable to simulate the behavior of the script using the Workbench Simulator.
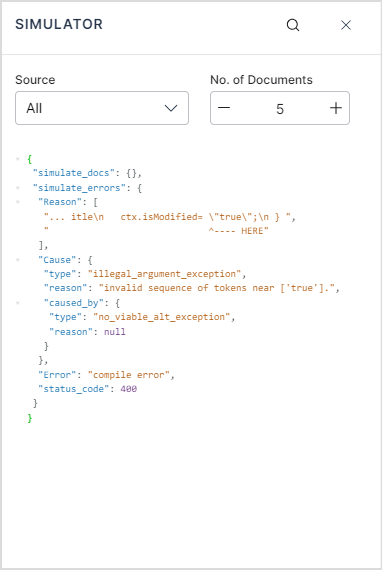
- Write the script and save the configuration. If there are any syntactical errors, you will get the following error message.

- Open the simulator to see the exact error message. Look for the
simulate_errorsobject. It will point to the exact line in the script where there is an error.