
In this model, the chunks are extracted from the ingested data at design time and relevant snippets are displayed when a user queries from the related data.
Chunking and Retrieval For Extractive Answers
For extractive answers, the chunks are extracted using a rule-based chunking strategy that uses headers and paragraphs under the header to identify chunks. The header and the text between the header and the next header are treated as one chunk. Each extracted chunk has a title and content field among other fields, stored in the index fields, chunk_title and chunk_text respectively. At the time of retrieval, these fields are used to calculate a similarity score that defines the match of the user query to that of the chunks. You can fine-tune the weightage given to these fields and the similarity score to choose the most suitable chunk to display. Chunks with a matching score greater than the similarity score are considered for answering.
Note:
- Here the chunk size is not customizable and depends on the document and how it is formatted. Images are skipped while extraction.
- This extraction model has certain known limitations and doesn’t work with all different types of formats.
- When an extractive answer is presented to the user, only the chunks generated by the Extractive model(Pattern-based extraction model) are used for the answer.
Extractive Answers Configuration
To enable the extractive model of answer snippets, use the slider at the top of the page. 
To use this model, configure the Similarity Score and Weightage for the chunk fields. 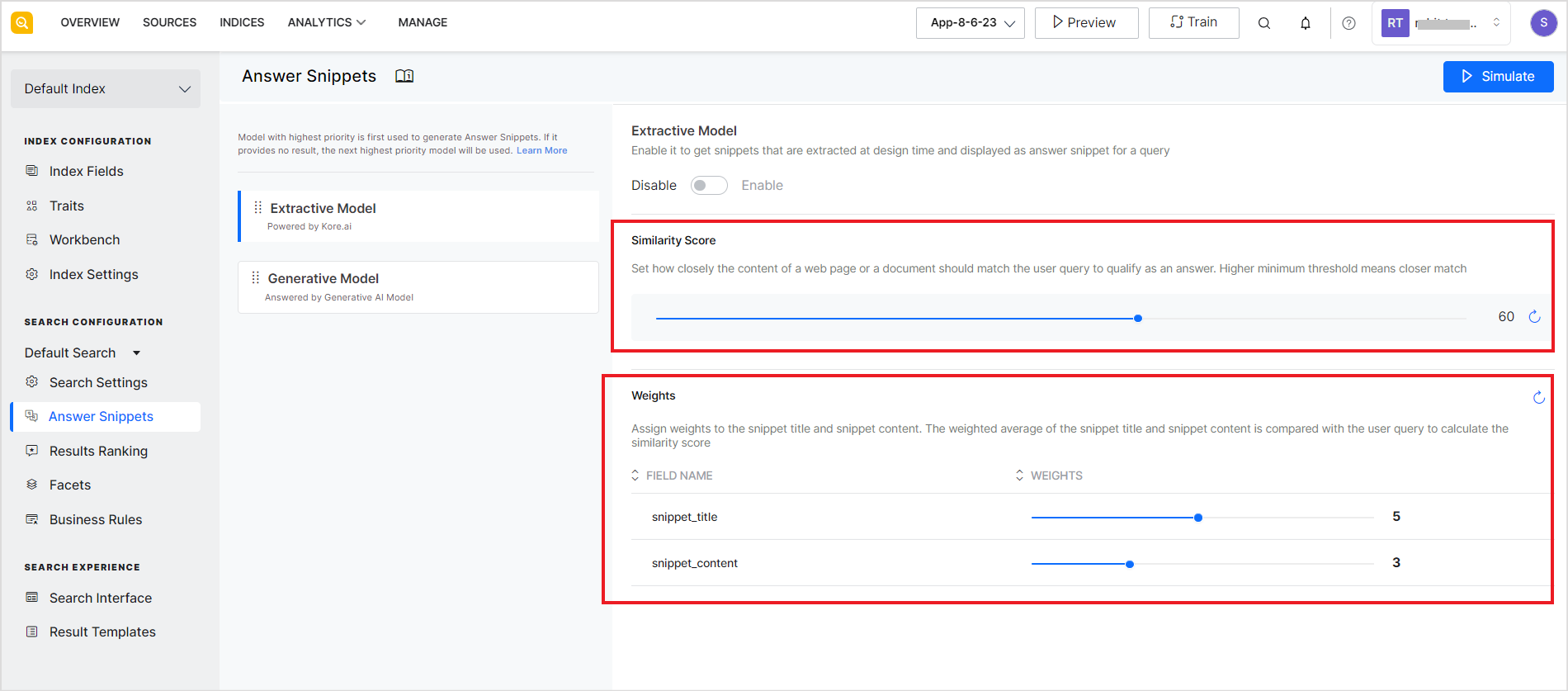
The Similarity Score is the minimum expected score of the match between the user query and the extracted answer snippet or the chunk. It defines how closely should a snippet match the user query to qualify as an answer. The higher the value of this field, the closer the match.
The weights section can be used to assign a weightage to the snippet_title and snippet_content fields. The average of the weights of the two fields is used in calculating a similarity score between the user query and a snippet. For example, if you assign a weightage of 9 to snippet_title and a weightage of 5 to the snippet_content, then the probability of getting chunks where title matches the user query better will be returned as the answer snippet.
snippet_title – This refers to the chunk_title field used to save the title of an extracted chunk.
snippet_content – This refers to the chunk_text field used to save the content of an extracted snippet.
If this similarity score calculated using the weights of the title and content fields is greater than or equal to the similarity threshold set above, the snippet qualifies as an answer snippet to be displayed to the user. If none of the snippets meet the similarity threshold, no snippet will be displayed.
Note that if the Extractive model is enabled for snippet extraction, a snippet extraction stage is automatically added to the Workbench. You can configure the stage to extract snippets as per your requirements. Find more details here.