Teams often spend time and effort deploying and testing custom configurations on live data. The simulator feature allows you to assess the impact of various search parameters on the content. You can see the data in real-time and the impacted fields based on the conditions applied without deploying the SearchAssist app.
A document is a record in which the applicable parameter occurs along with relevant data. The Workbench comes with a built-in simulator that has an interactive preview of how the stage rules affect a document before it’s indexed.
Click Simulate to evaluate each indexing stage on a sample set of documents. The simulator panel shows the relevant data and records depending on the configured stage and conditions applied.
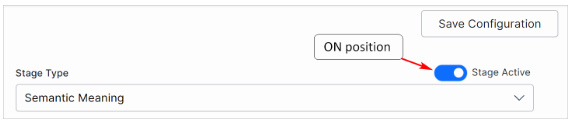
You can simulate multiple stages together in the required order. The simulator can display up to 20 documents or records. To skip a stage in simulation, switch the Stage Active toggle to OFF. The default setting is ON.
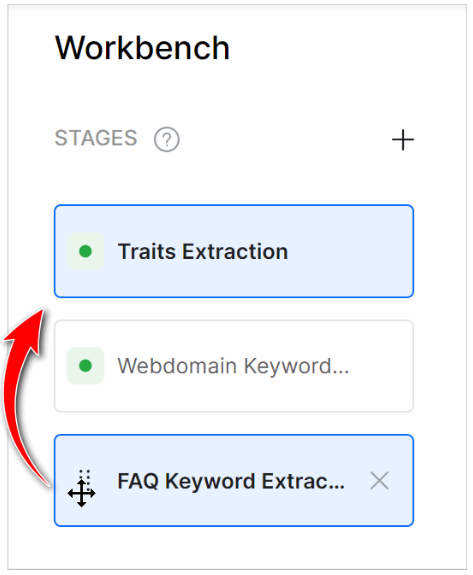
The order of stages can also affect simulator results. For example, you have three active stages in this order: Traits, Webdomain Keyword, and FAQ Keyword Extraction. Click Simulate in the Web domain keywords stage to extract Traits and Web domain keywords. Results from forward stages (e.g. FAQ Keyword Extraction) are not included. If you want results from all three stages, click the simulation button in the last stage.
You can change the order of a stage in the Workbench. Click a stage handle and drag it to a new location.