Use this file to discover all available pages before exploring further.
Back to Search AI connectors listThe Confluence Cloud Connector integrates Search AI with your Atlassian Confluence Cloud account, enabling intelligent search over your organization’s knowledge articles using OAuth 2.0 authentication.
Specification
Details
Repository type
Cloud
Supported API version
REST API v1
Supported content
Knowledge Articles
Access control support
Yes
Only manually created Knowledge Articles are supported. Searching through other uploaded content types such as PDF files, docs, and images is not supported.
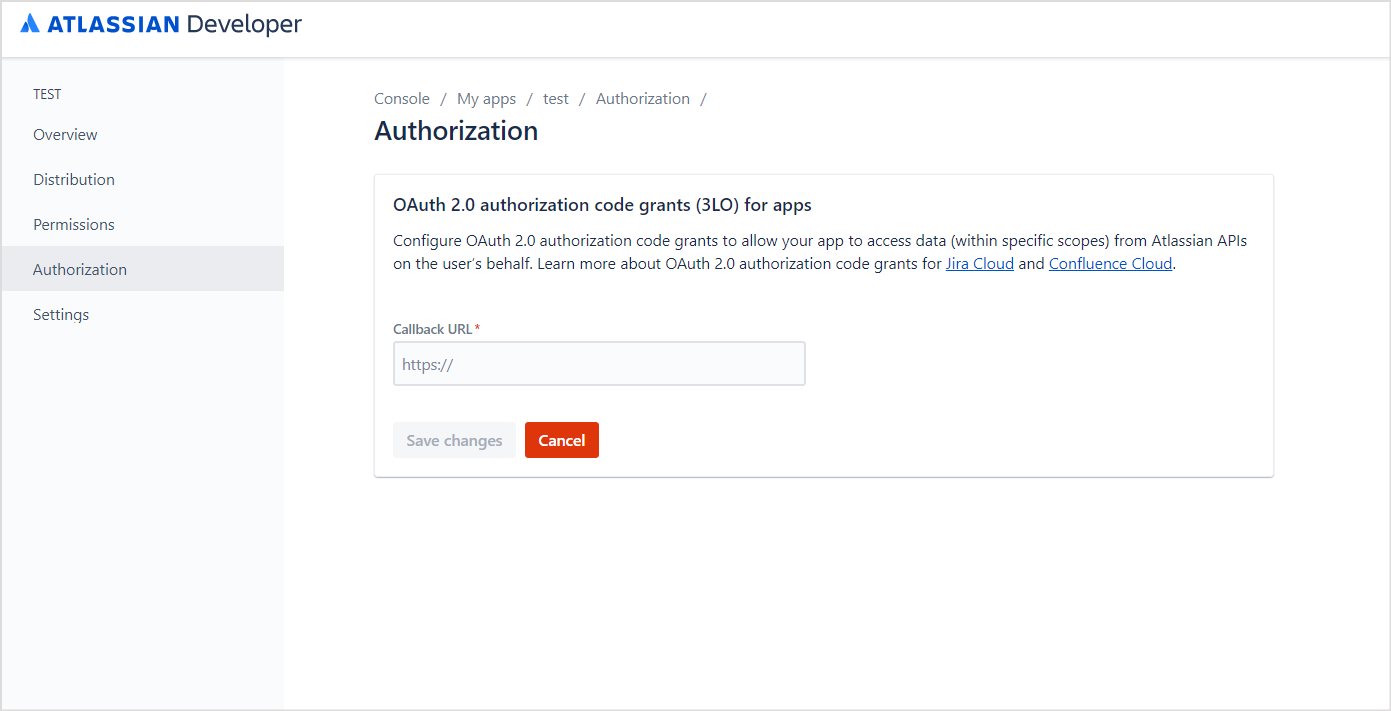
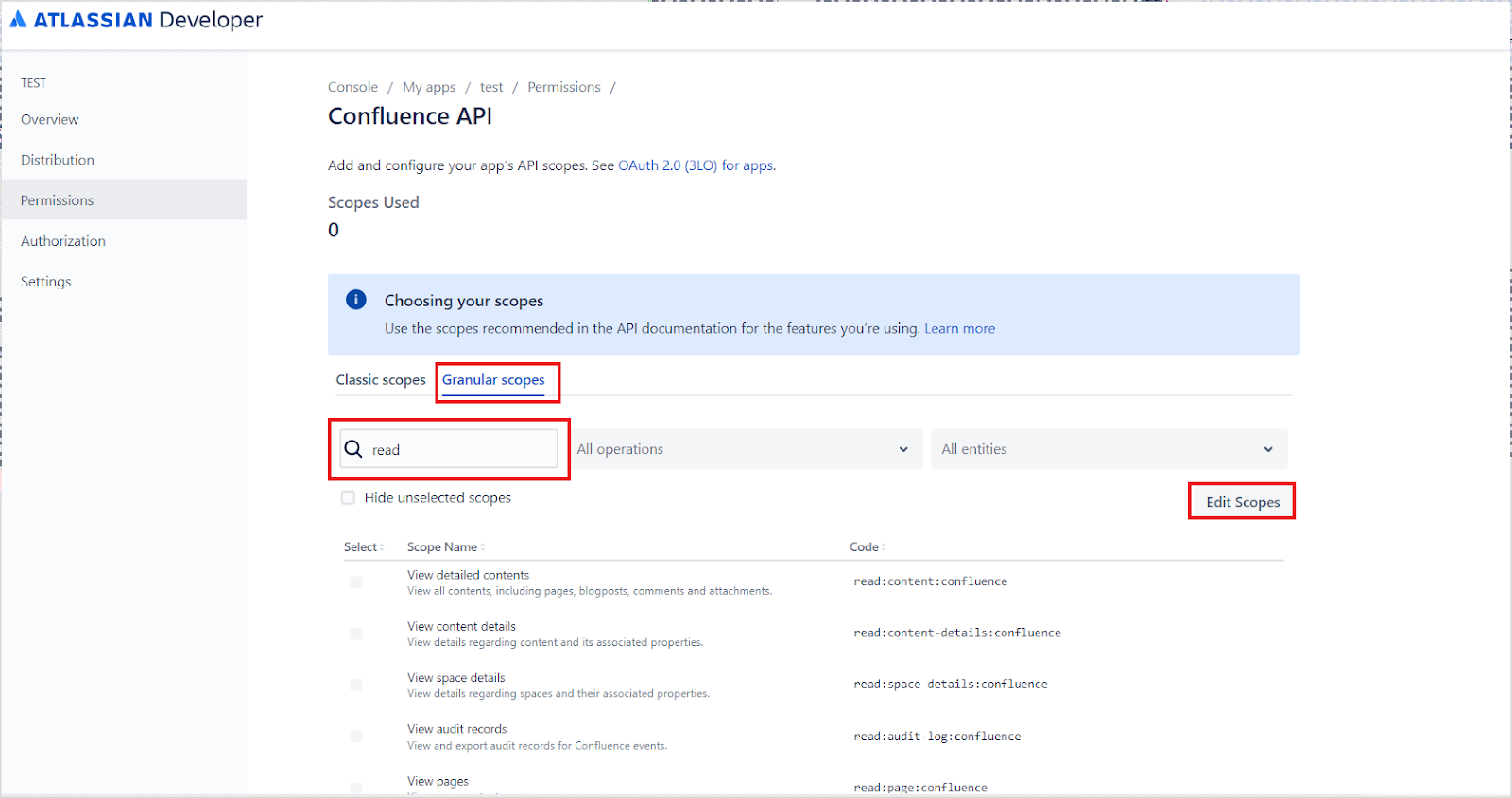
Step 1: Configure an OAuth Application on Confluence Cloud
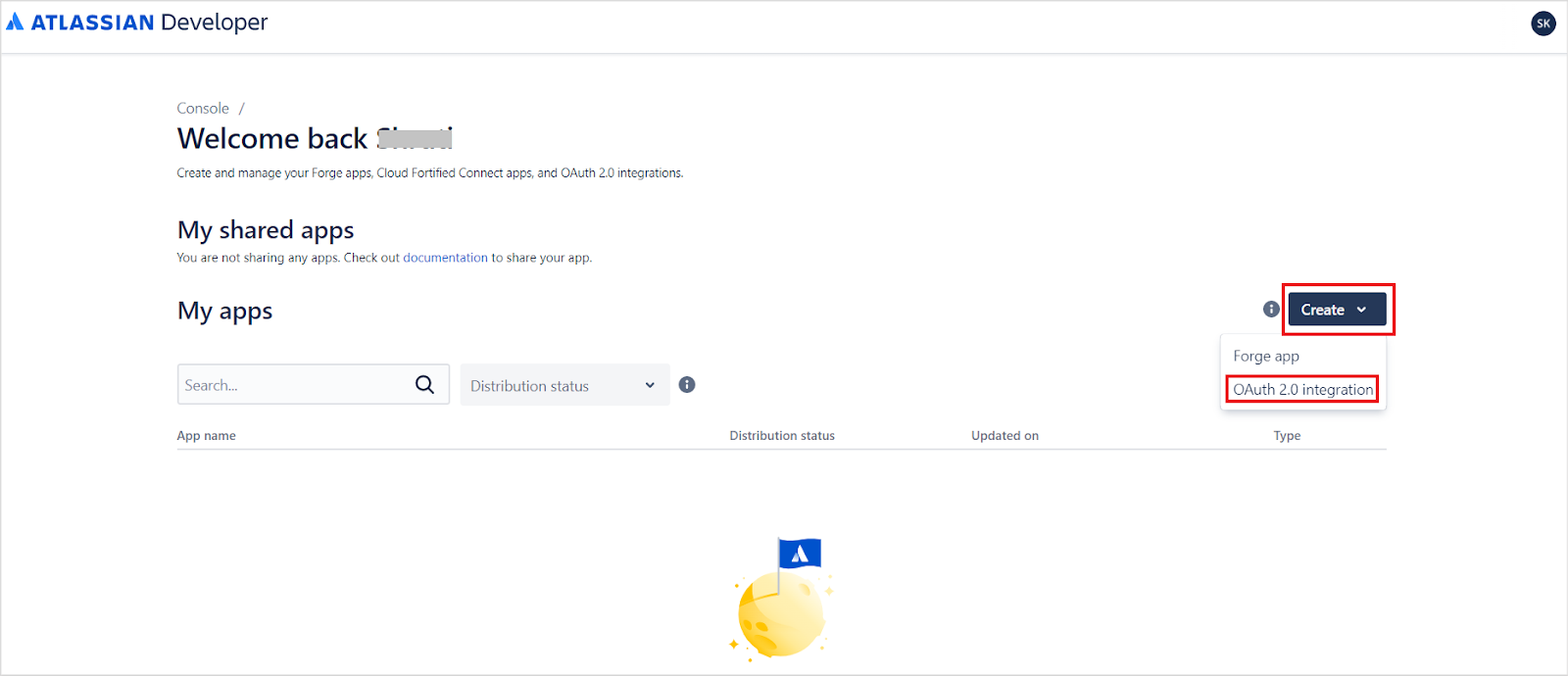
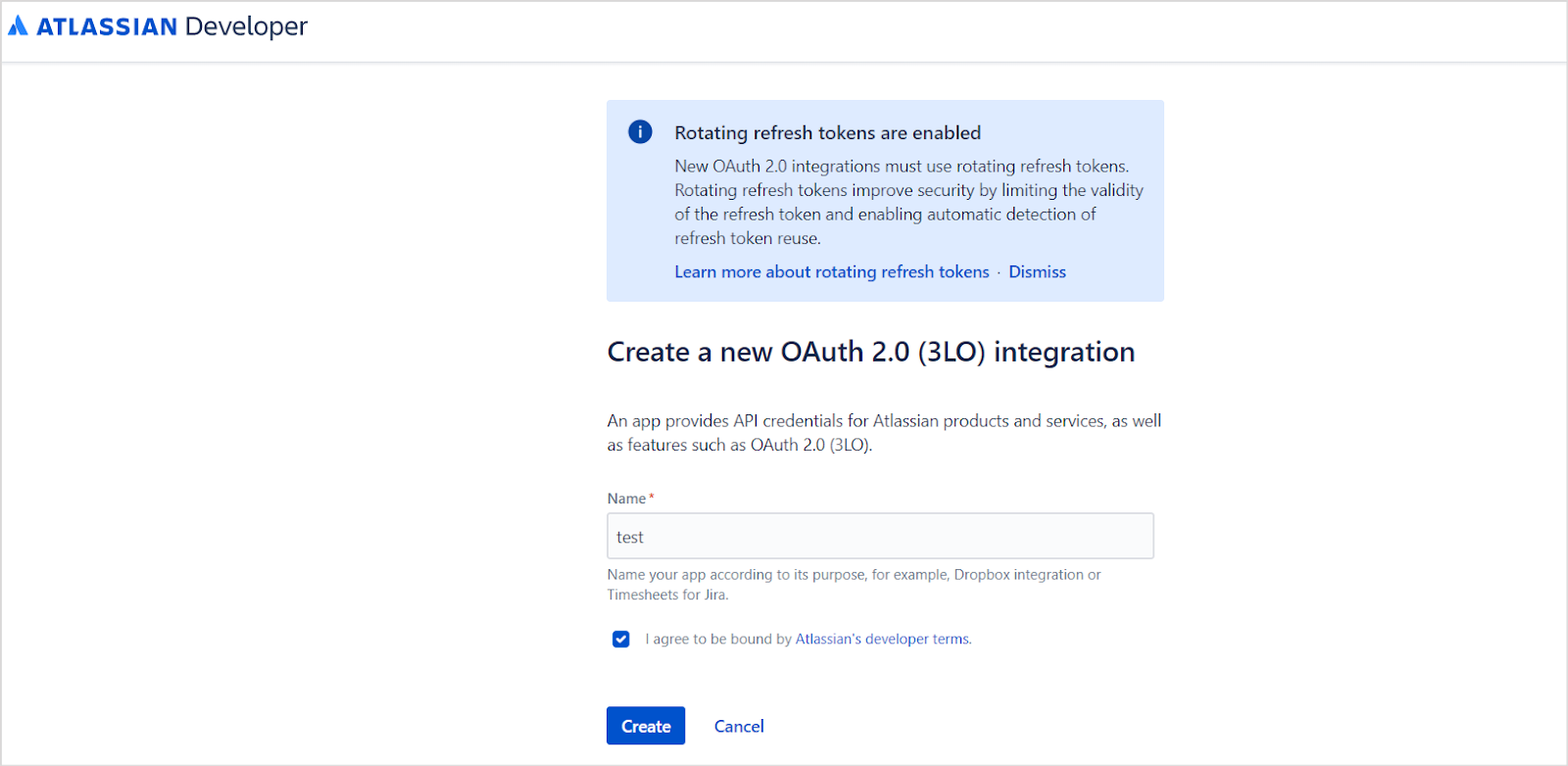
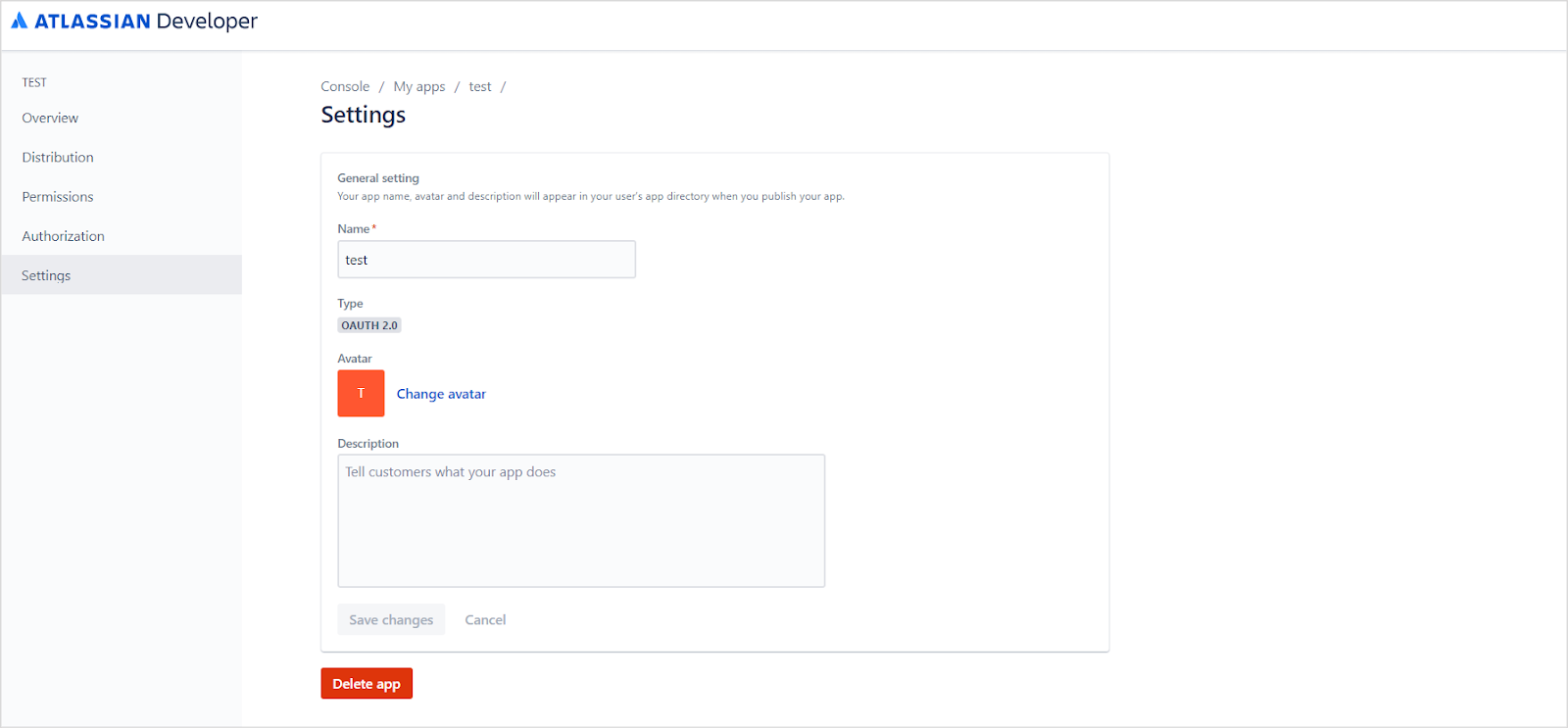
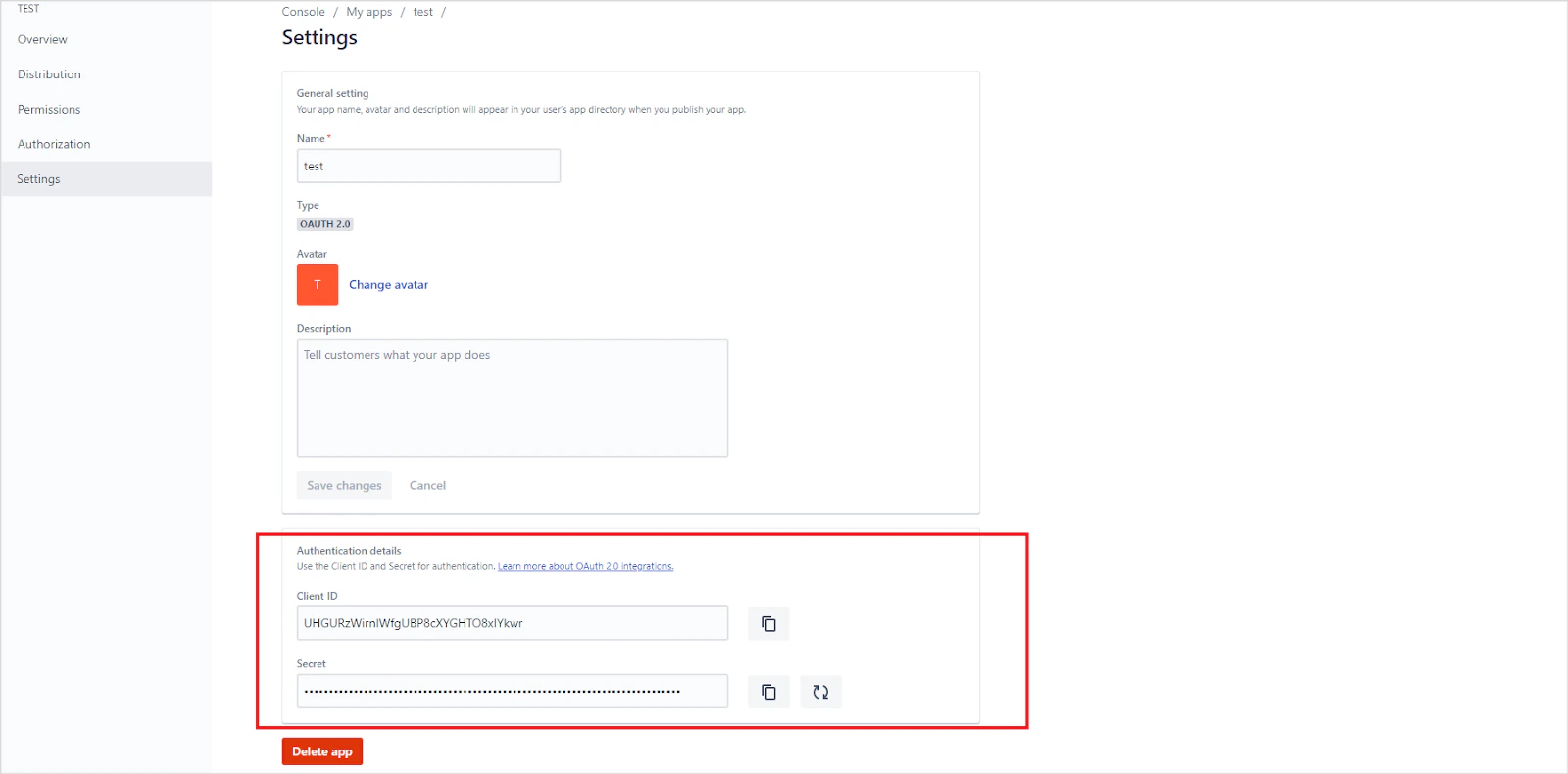
Sign in to your developer account at the Atlassian Developer Portal. Click your profile name at the top right and navigate to the Developer Console.The Developer Console lists all your apps.Click Create and select OAuth 2.0 Integration.Provide a name for the application and click Create.Update the application name and description from the Settings tab, optionally add an avatar, and click Save changes.
A single Confluence Cloud connector supports multiple authentication profiles, allowing it to sync content from multiple Confluence Cloud accounts. Each profile authenticates independently using its own OAuth 2.0 credentials and syncs content from spaces accessible to that authenticated user.Content accessible by multiple profiles is deduplicated automatically - no duplicate search results appear. Deleting a profile removes only content exclusive to that profile; content shared with other profiles remains accessible.This simplifies multi-account management, reduces the need for multiple connectors, and improves scalability for enterprise use cases.
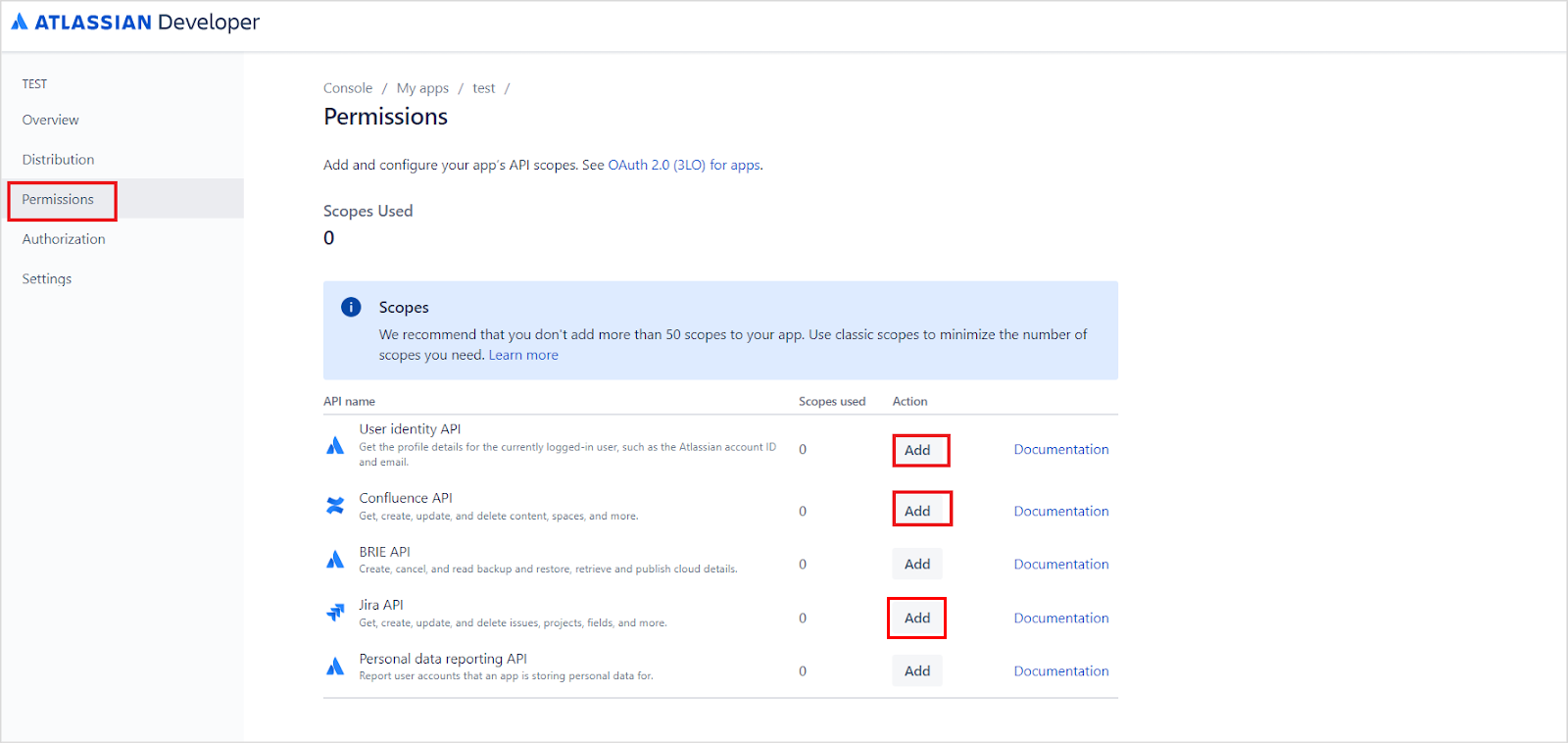
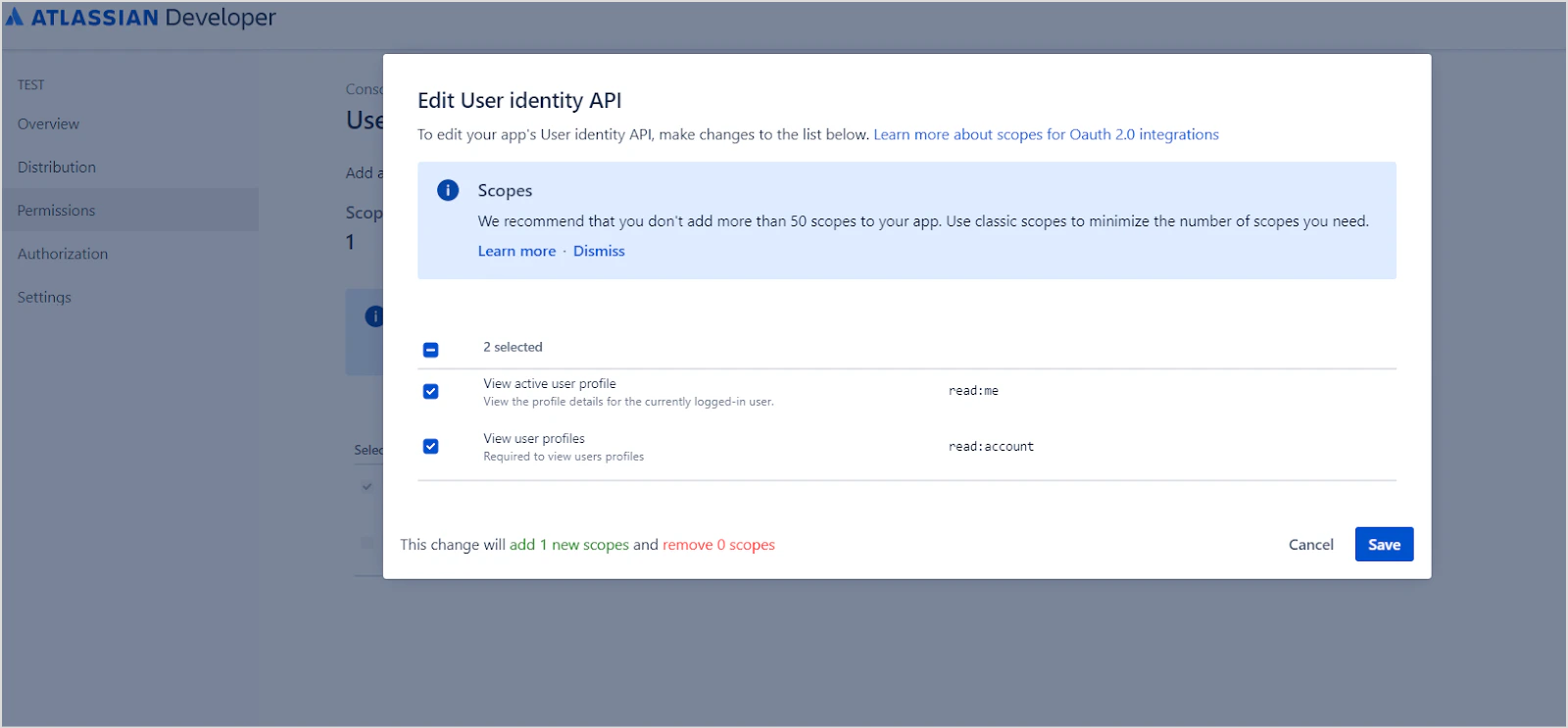
To selectively ingest content, select Sync Specific Content and click Configure. Define rules using a parameter, operator, and value.Supported filter parameters:
Parameter
Description
Ancestor
Direct child pages and descendants of given content IDs
Content
Specific content by content ID
Created
Content by creation date (yyyy/mm/dd hh:mm, yyyy-mm-dd hh:mm, yyyy/mm/dd, yyyy-MM-dd)
Creator
Content created by specified user account IDs
Label
Content filtered by label
Parent
Content under a given parent
ID
Content by content ID
Space
Content in a specific space
Title
Content by page title
User
Content by user ID
You can also add custom CQL fields. Refer to the complete list of supported CQL fields.The Operator field accepts values such as equals, not equal, and contains, depending on the selected parameter.Example: Ingest all pages and sub-pages under a given ancestor:Example: Ingest only pages created or modified after January 1, 2024:
Use the OR operator to combine multiple rules for different content types.
Use the AND operator within a rule to apply multiple conditions. For example, to ingest content created after January 1, 2024 with “SearchAI” in the title:
Manual sync — Click Sync Now on the Configuration tab to immediately ingest all updates from Confluence Cloud.Scheduled sync — Enable Schedule Sync and set the date, time, and frequency to keep content automatically up to date.
After the first full sync, subsequent syncs automatically fetch only content that has been created or modified since the last successful sync. This makes syncing significantly faster for large Confluence instances.Each authentication profile maintains its own independent sync cursor. A full sync is automatically triggered when:
Search AI supports access control for content ingested via the Confluence Cloud Connector. Go to the Permissions and Security tab and select the access mode:
Permission Aware - Honors user permissions from Confluence Cloud. Users can only view search results for content they can access in Confluence.
Public Access - Overrides Confluence permissions. All users can access all ingested content regardless of their Confluence permissions.
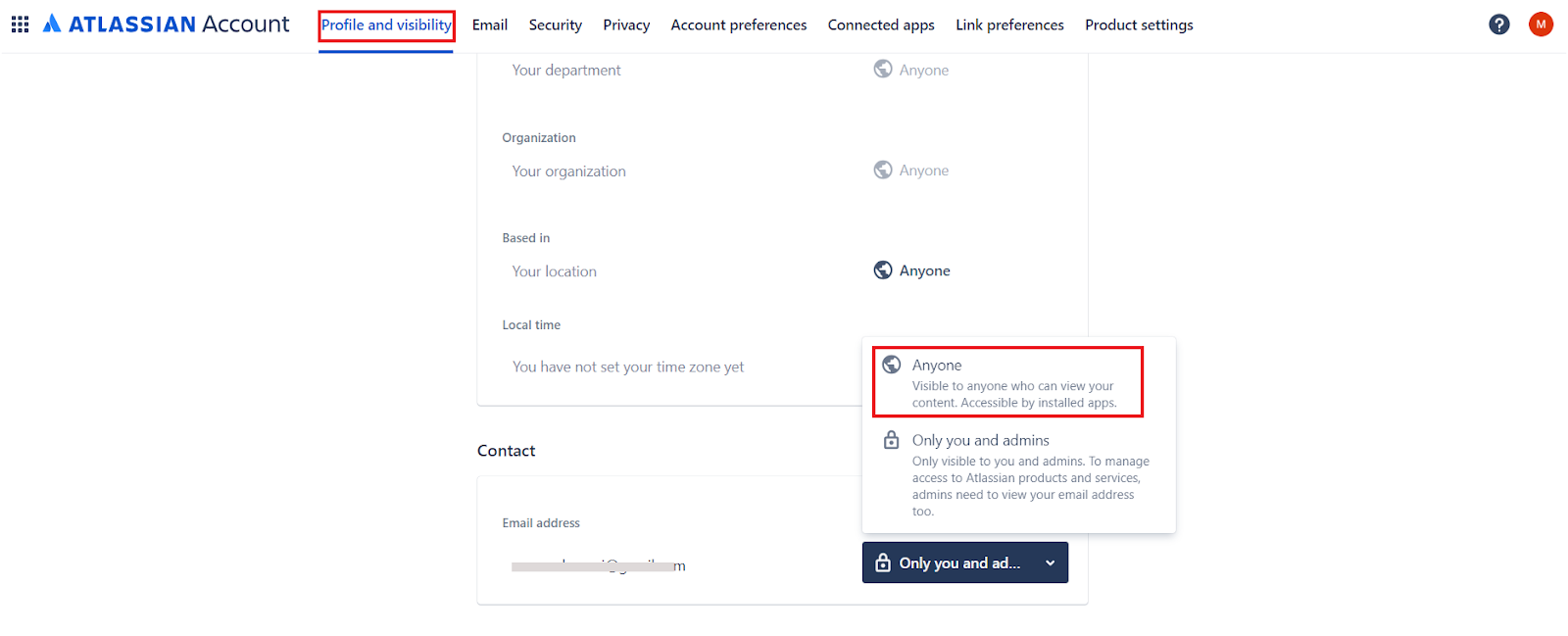
Access control relies on user email addresses as unique identifiers. The account used to configure the connector must be able to view user email addresses. Use an admin account or ensure users have enabled the required settings in their Confluence profiles.
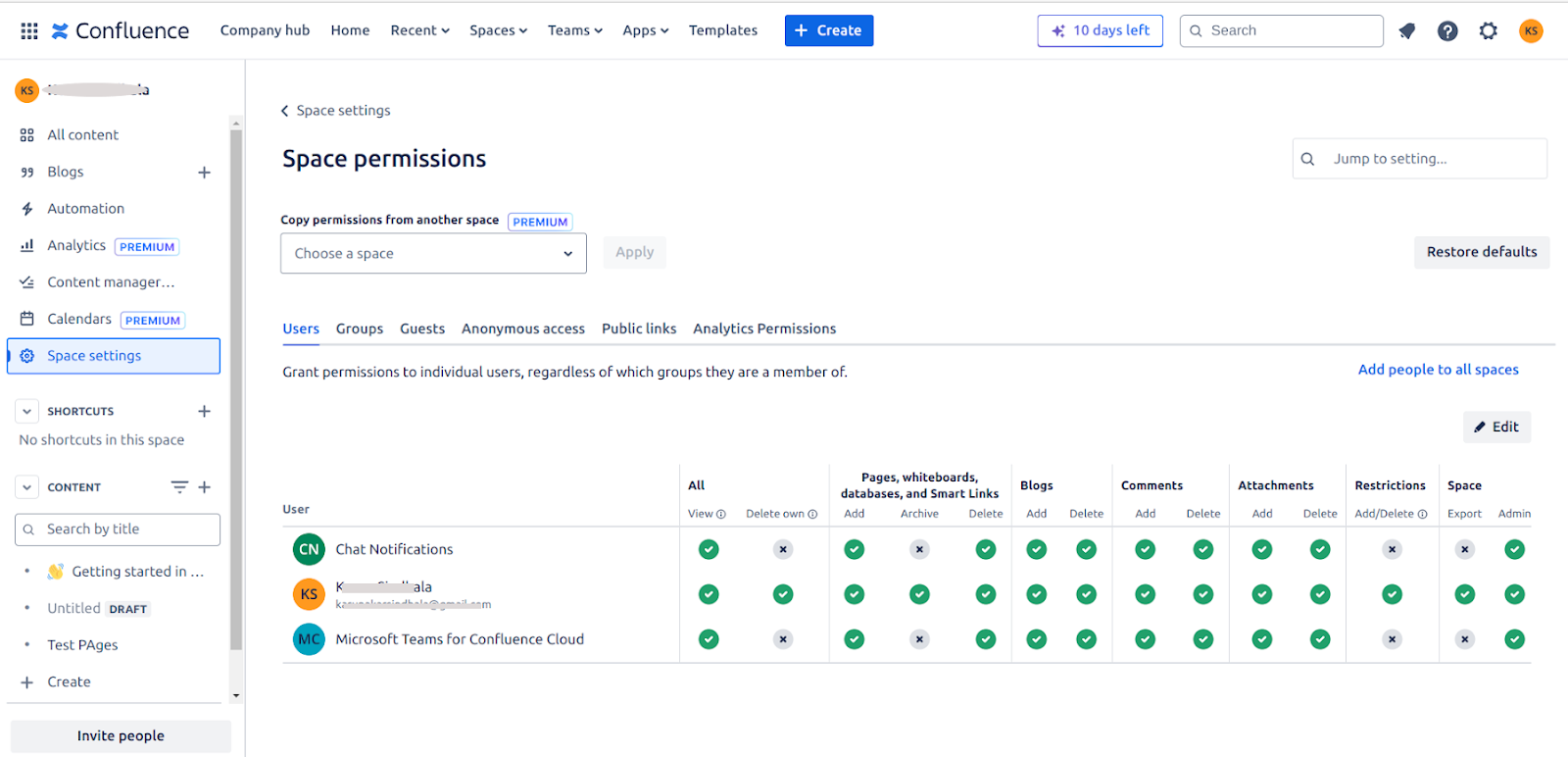
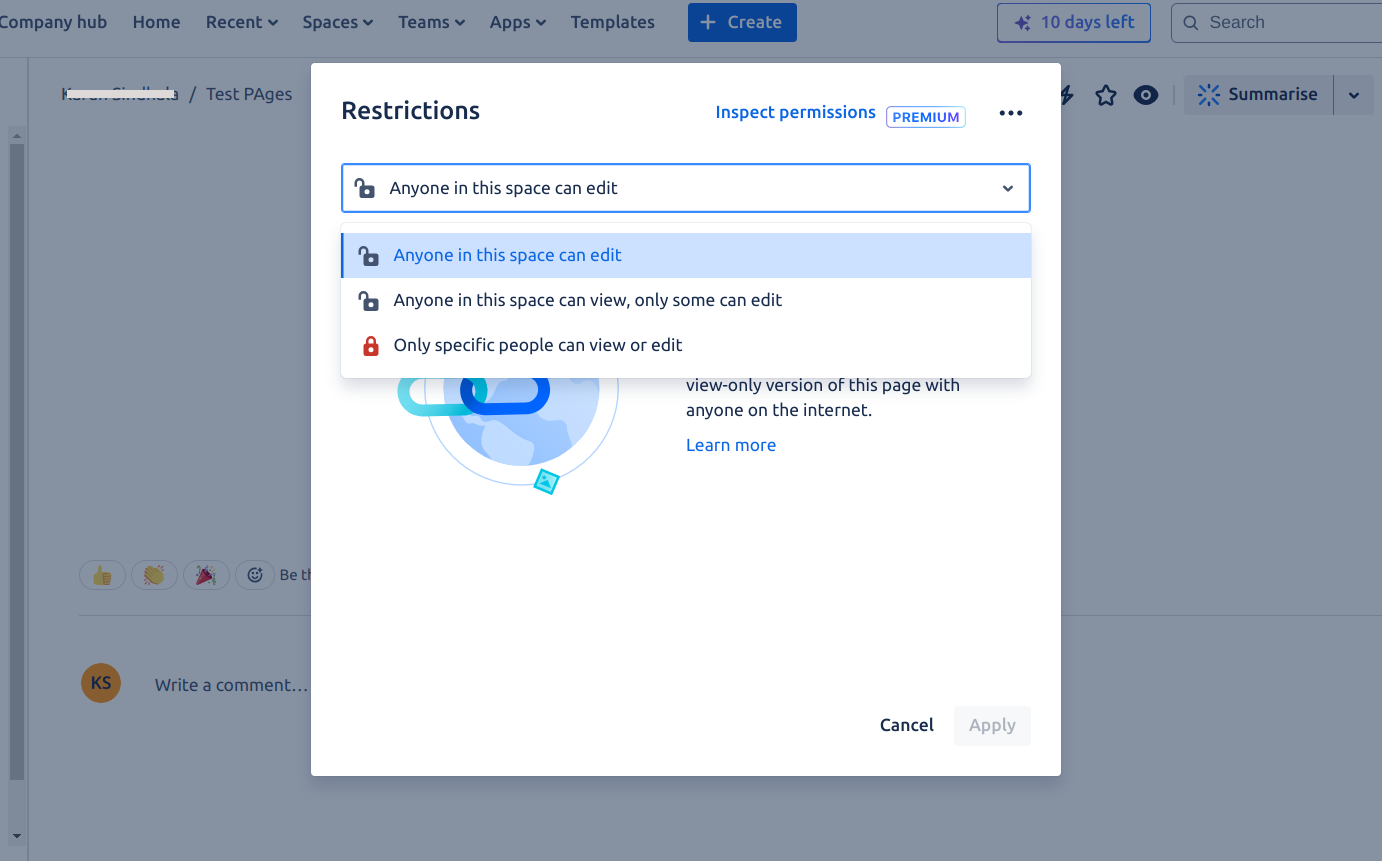
Space Permissions — Each space has an independent set of permissions managed by space administrators. Search AI requires at minimum view permission to allow a user to access the content.Page Restrictions — Pages inherit space permissions but can define their own restrictions. If a page is set to “Only specific people can view & edit,” space permissions are not applied.
Search AI uses the sys_racl field to control who can access ingested content. The value stored in sys_racl depends on whether the document is public or private:
Public documents - The organization’s domain name is included in the sys_racl field. This ensures that only internal employees belonging to that domain can access the content, rather than allowing unrestricted public access.
Private documents - The space name is included in the sys_racl field. Access is scoped to users who have permissions within that specific Confluence space.
Individual access — Users added directly to a space or page are listed in the sys_racl field of the indexed content by their email address. These users can directly access the content based on their permissions.
Group access — When access is granted to user groups, Search AI creates a corresponding permission entity for the group. The sys_racl field stores the permission entity IDs. Add users to the permission entity using the Permission Entity APIs to grant access.
User Onboarding - When onboarding users, all users must be registered with their associated domain name in Search AI. This ensures that domain-based access control for public documents functions correctly and that the right users are granted access to content scoped to their organization’s domain. Use the Permission Entity APIs to associate users with their domain and the appropriate permission entities for group-based access.