
- If a PII value is used in Dialog Task transitions, the platform automatically uses the original value for transition condition evaluation, such as validating the entity value’s format (for example, checking if it’s a valid number).
- If a PII value is used in the Service Node definition, the platform uses the redacted value by default to make service calls. However, you can send the original data for scenarios like passing the value to a backend system. Select the appropriate option while configuring the Service Node.
- You may use the Redaction of PII Data configuration of the Entity Nodes to present the original values of a redacted entity to users for confirmation. Select the appropriate option while configuring the Entity Node.
The ‘Redaction of PII Data’ option selected at the node level only affects those instances during runtime or live interaction. PII data is always redacted/masked in chat history and internal logs, irrespective of the option selected at the node level.
The platform provides three modes to redact specified information types:
| Option | Description | Example |
|---|---|---|
| Redaction | Replaces the data with a unique random alphanumeric value | An email address gets replaced with a random value such as jjh4ezb2 |
| Replacement | Replaces the data with a static value that you enter in the PII Redaction settings | If the static value entered is asdf1234, any email address entered is replaced with asdf1234 |
| Mask with Character | Replaces the first few and last few characters of the data with + or # symbols. You can select the number of characters to mask and the symbol for masking. | If you configure the first four and last four characters to be masked with +, an email address such as helpdocs@kore.ai gets redacted as ++++docs@kor++++ |
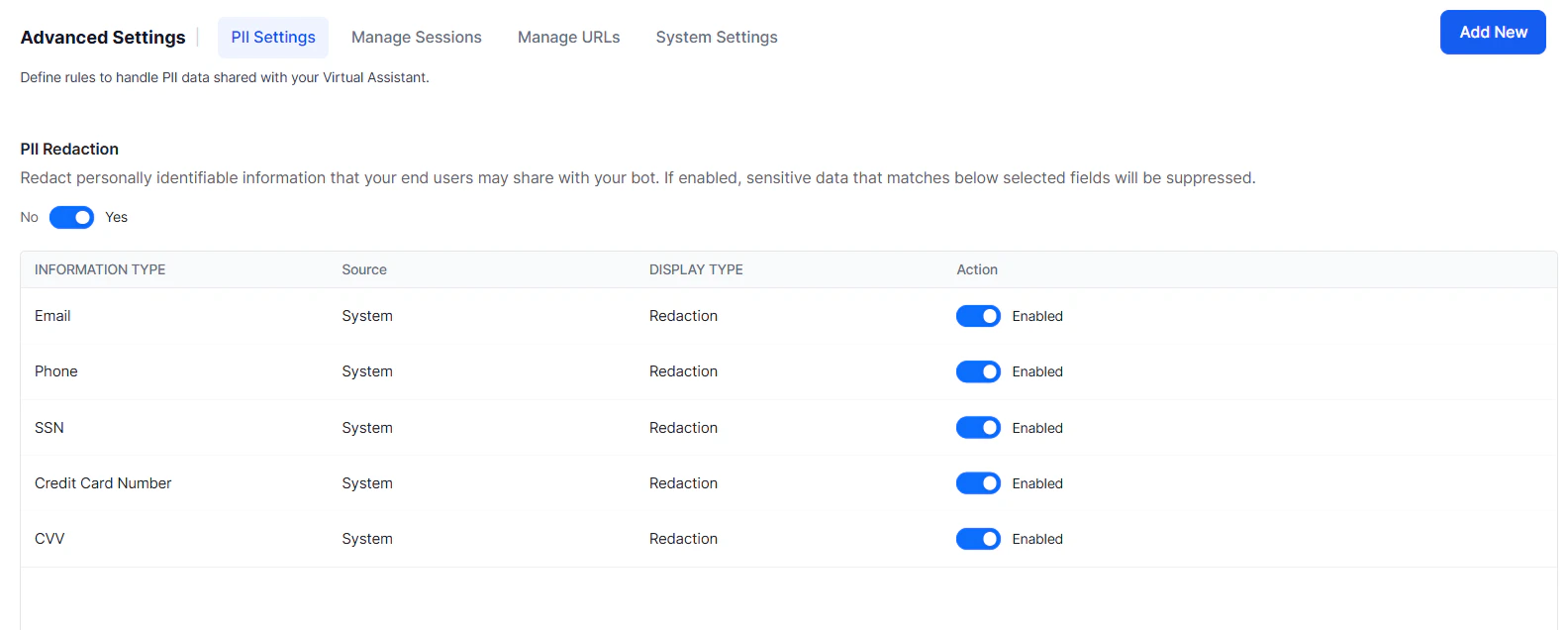
How to Redact
- Open the App for which you want to configure PII settings.
- Navigate to App Settings > Advanced Settings > PII Settings.
- The PII Redaction page opens.
- If PII Redaction is not enabled for the app, toggle the switch to Yes. The page now shows a list of information types whose redaction settings are configured by default.
- To activate redaction for any out-of-the-box information type, toggle the switch next to it to Enable. To edit redaction settings, click the information type name.
- To configure redaction settings for other information types, click Add New in the top-right corner of the PII Redaction page.
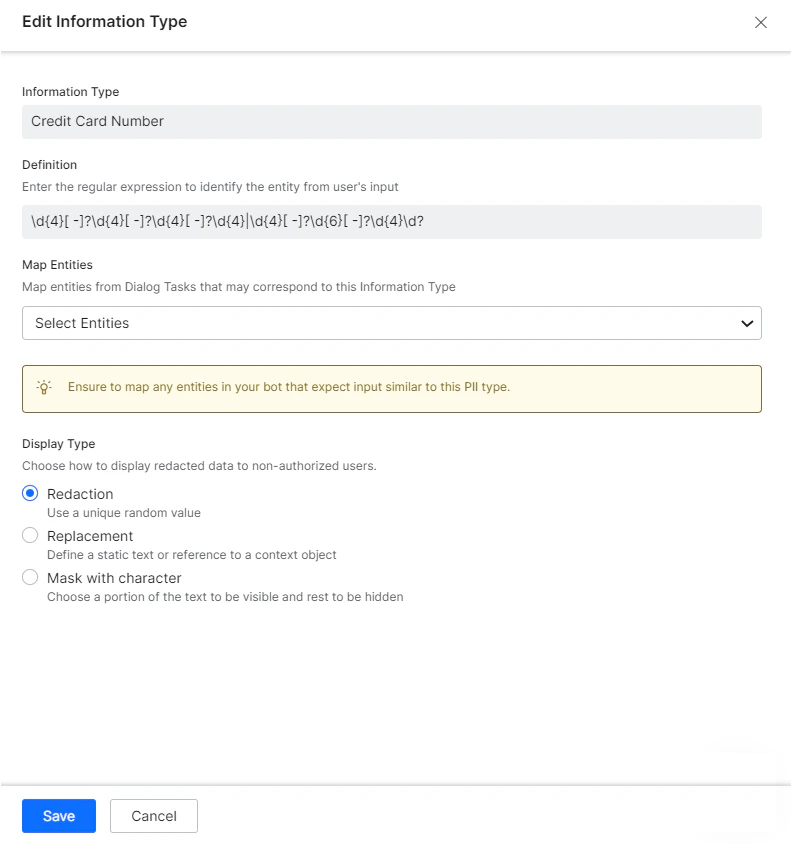
Configuration Fields
| Field | Description |
|---|---|
| Information Type | Enter a name for the information type you want to secure, for example, Credit Card Number. |
| Definition | Enter a regular expression for recognizing the information type from user entries. For example, a regex for a Visa credit card could be ^4[0-9]{12}(?:[0-9]{3})?$ |
| Map Entities | Map all the entities in the app’s Dialog tasks that correspond to the information type. Note: If you do not map entities corresponding to redacted information types, even valid user entries for those entities cause errors in the dialog tasks. For example, if redaction is enabled for the email information type and a user enters an email address, the platform redacts it before the entity node captures it. The entity node receives redacted data and, since the entity isn’t mapped in the redaction settings, treats the redacted value as an invalid email entry. Mapping the entity in the redaction settings allows the entity to recognize the redacted data and accept it. |
| Display Type | Select one of these modes to display the redacted data anywhere in the platform: Redaction, Replacement, Mask with Character. Note: The displayed value is prefixed with a platform-generated random unique identifier, which is the key used internally to retrieve the original value for conditional transitions. |
Configure Contextual Sensitive Data
The Kore.ai XO platform allows you to secure sensitive data input during a conversation. Enabling sensitive data redaction and using custom regex patterns to identify and secure sensitive information is an effective approach. Enable the Sensitive Entity settings at the Entity Node to secure sensitive user input such as PINs or OTPs (typically 4 to 6-digit numbers). These values must not be stored in plain text in conversation logs or chat history. Redacting or masking at the entity node level prevents plain-text storage, reducing the risk of unauthorized access or misuse. Custom regex patterns allow the AI Agent to identify and handle sensitive information based on conversation context, balancing conversational functionality with data security.Sensitive Data Use Case Scenarios
Scenario 1: String patterns for sensitive data conflict or overlap in different contexts. For example, a password is 6-8 digits, and a phone number (TPN) is 9 to 12 digits long. In TPN cases, a user may miss typing a digit or two. Due to the password PII pattern of 6-8 digits, the TPN gets masked as if it’s a password, and TPN entity recognition fails. Enabling the Sensitive Entity setting redacts and replaces contextually sensitive data to resolve this conflict. Scenario 2: A customer tries to change their password by interacting with the AI Agent. Passwords are sensitive and must be secured everywhere. However, defining a PII pattern for passwords may mask or redact other inputs that match the same pattern.PII vs. Sensitive Entity
- Personally Identifiable Information: Identifies and redacts or masks sensitive data in common PII categories, such as Social Security Numbers, email addresses, or credit card numbers. Provides a broad, predefined set of sensitive data patterns detected and handled uniformly across the entire conversation.
- Sensitive Entity: Provides fine-grained control and customization of redaction or replacement actions based on specific sensitive data contextual conditions. Enables you to define rules specific to your use case, where the same sensitive data pattern may require different handling depending on context.