Select and Deploy an Open-Source Model¶
Currently, GALE supports thirty-plus open-source models and provides them as a service. If you select the Kore-hosted model, you can optimize it before deployment.
To select and deploy a model, follow these steps:
-
Go to Models > Open-source models and click Deploy a model.

-
The Deploy dialog is displayed. In the General details section:
-
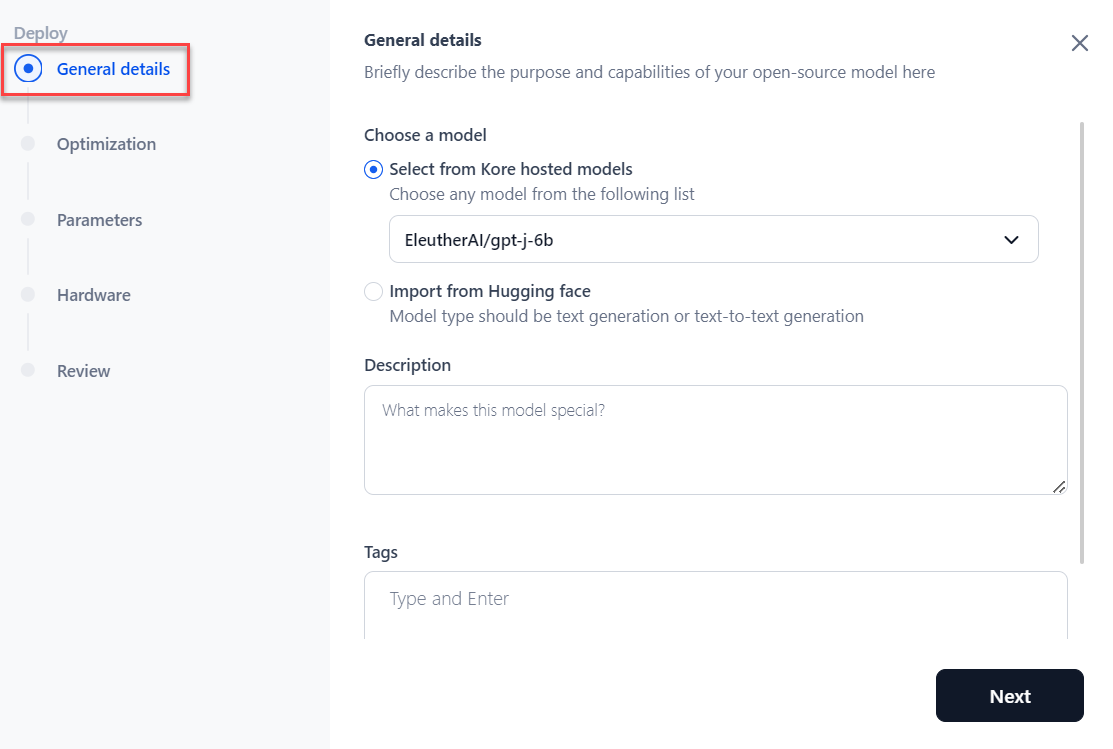
If you choose Kore-hosted models, select the model from the dropdown menu. Add a Description and provide tags to ease the search for the model and click Next.
-
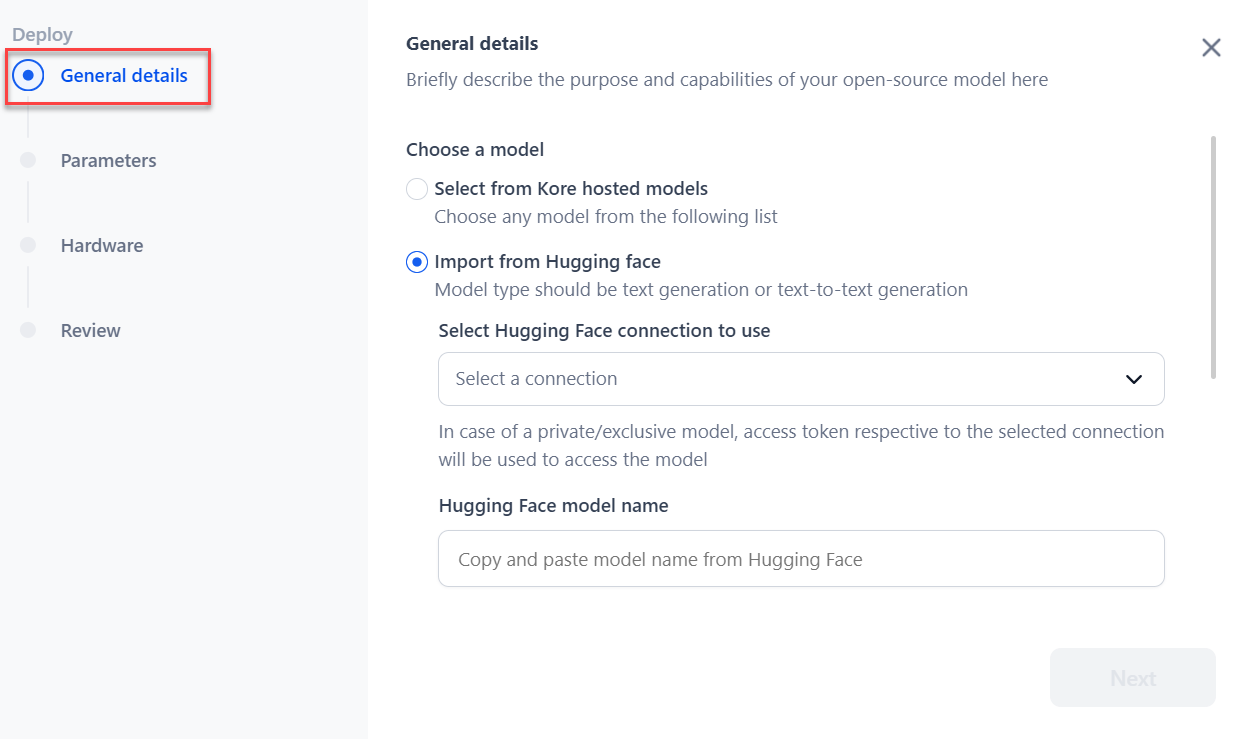
If you choose to Import from Hugging Face, select the Hugging Face connection type from the dropdown and paste the model name. For more information about connecting to your Hugging Face account, see How to Connect to your Hugging Face Account.
Note
In the case of public mode, selecting a connection is not necessary.
-
-
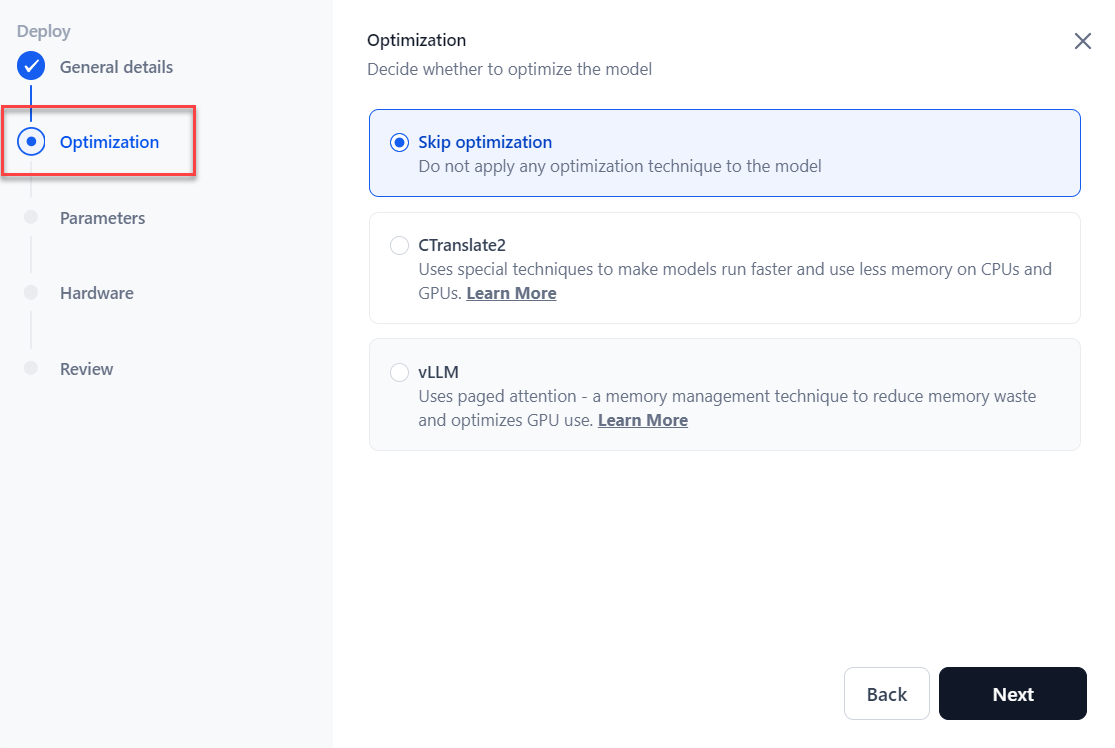
Based on the selected Kore-hosted model, the Optimization section is displayed. Choose the optimization option as required and then click Next. Learn more.
- Skip optimization: It skips the model optimization.
- CTranslate2: Select Quantization from the dropdown menu if applicable. Learn more.
-
vLLM: Select Quantization from the dropdown menu if applicable. Learn more.
-
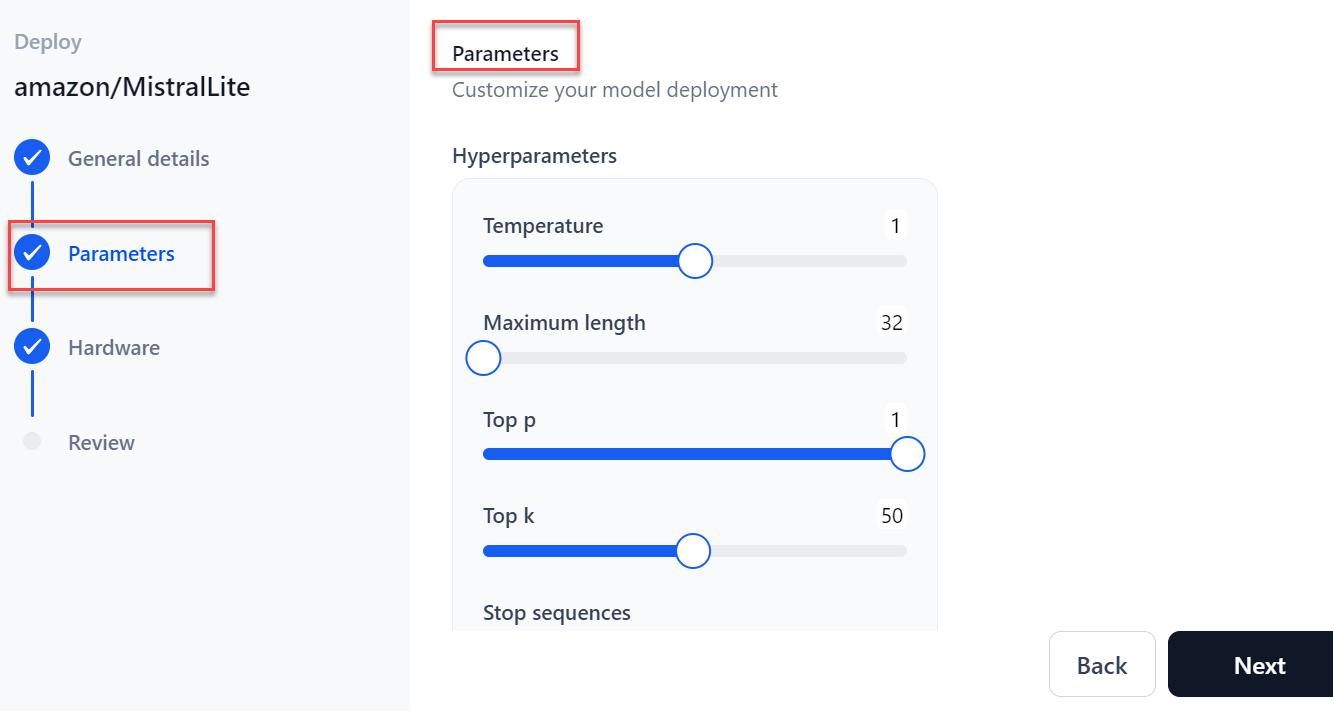
In the Parameters section:
- Select the Sampling Temperature to use for deployment.
- Select the Maximum length, which implies the maximum number of tokens to generate.
- Select the Top p, an alternative to sampling with the temperature where the model considers the results of the tokens with top_p probability mass.
- Select the Top k value, the highest probability vocabulary tokens to keep for top-k-filtering.
- Enter the Stop sequences, which tells the model when to stop generating further tokens.
- Enter the Inference batch size, which is used to batch the concurrent requests at the time of model inferencing.
- Select the Min replicas, which indicates the minimum number of model replicas to be deployed.
- Select the Max replicas, which indicates the maximum number of model replicas to auto-scale.
- Select the Scale-up delay (in seconds), which indicates how long to wait before scaling up replicas.
-
Select the Scale down replicas (in seconds), which indicates how long to wait before scaling down replicas.
-
Click Next.
-
In the Hardware section, select the required hardware for deployment from the dropdown menu and click Next.
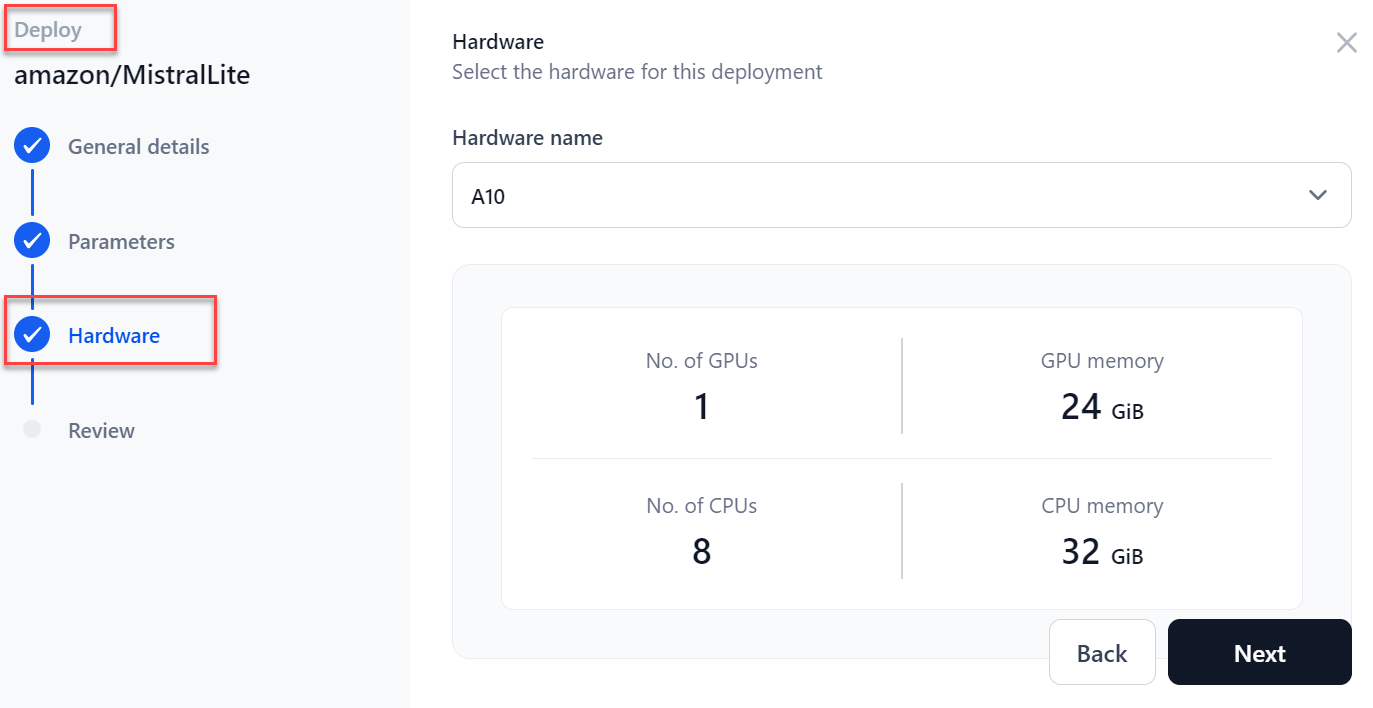
-
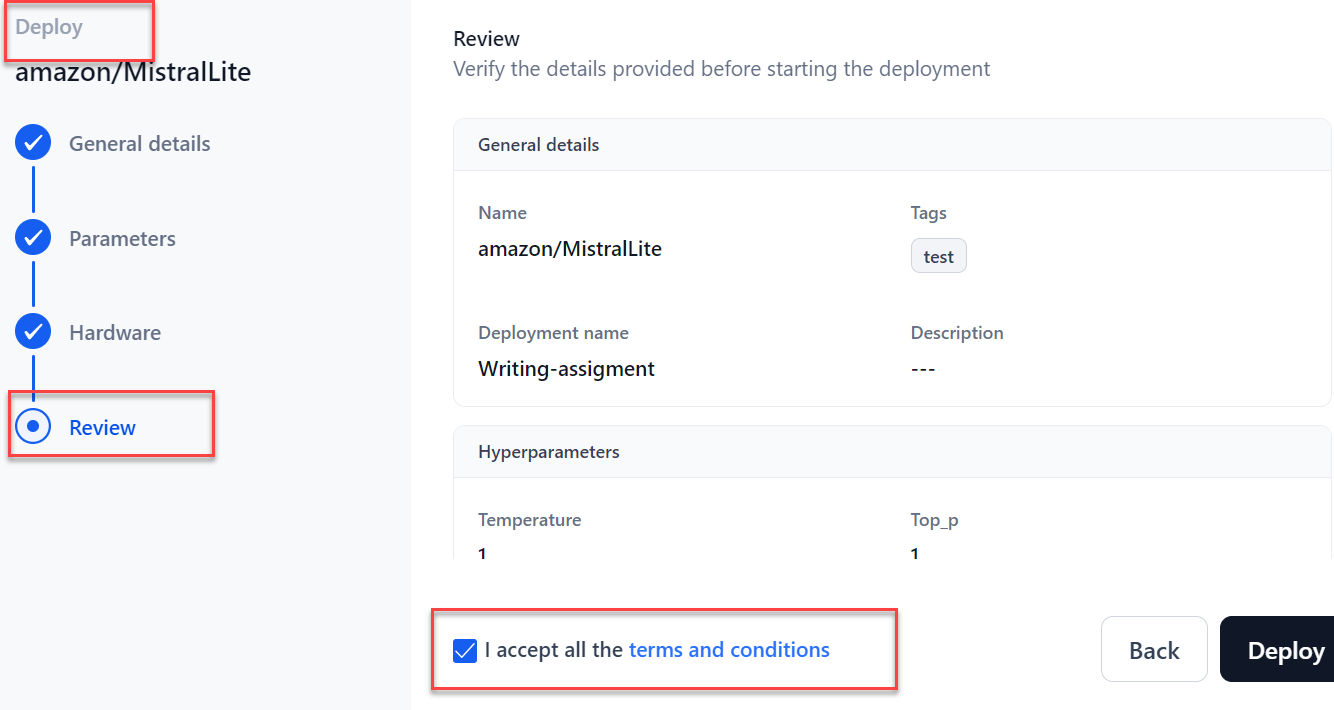
In the Review section, verify all the details before starting the fine-tuning. To modify previous steps, click Back. Go through the terms and conditions and tick the checkbox I accept all the terms and conditions.
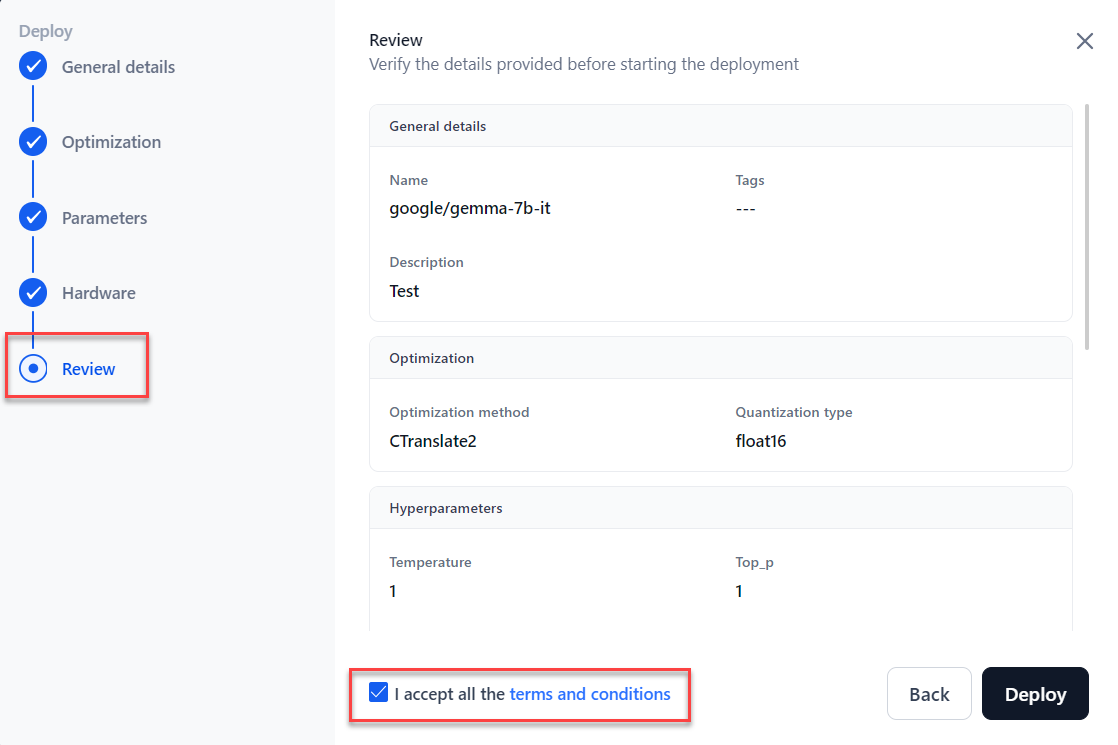 8. Click Deploy.
8. Click Deploy.Note
You will be charged for deployment and inferencing-related costs for each open-source model.
{kind=link}
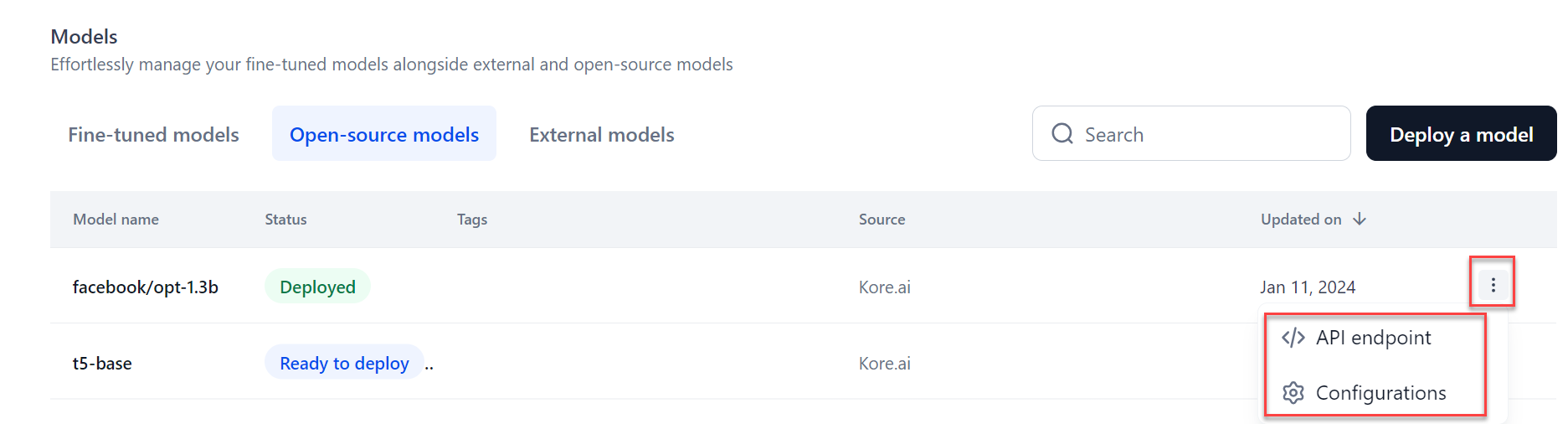
If you have selected optimization, the model optimization starts, and the status changes to “Optimization”. If not, the model is deployed. After deployment, the status changes to "Deployed." You can now use this model across GALE and externally.
Hover over the deployed model to view more icons (three dots) which provide access to the model API endpoint and Configurations. Selecting the API endpoint option shows the API endpoint, deployment history, API keys, and other details. Selecting the Configuration option allows you to add a description, tags, and deploy or delete the model.
Re-deploy a Deployed Model¶
After the initial deployment, if you wish to update the model’s parameters, hardware, or both, you must redeploy the updated model.
To re-deploy a deployed model, follow these steps:
- Go to Models > Open-source models and select a model to redeploy.
- Click the Deploy model. The Model Configuration page is displayed.
- Modify the required fields and click the Deploy. Once deployed, the status changes to “Deployed”.