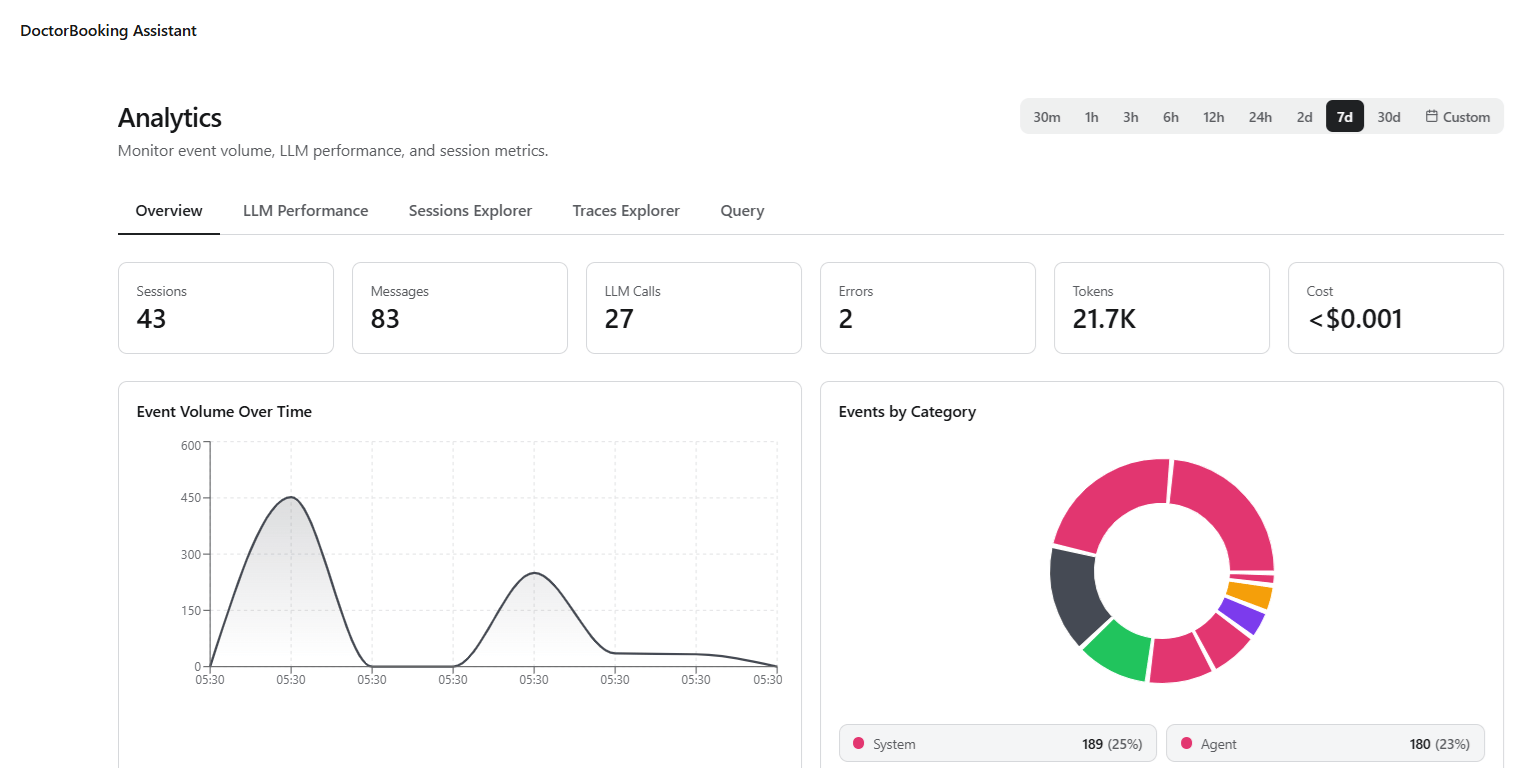
Dashboard
The Dashboard page — titled At a Glance in the interface — provides a pre-built executive overview of your AI agent program. It aggregates key performance indicators, trend visualizations, outcome breakdowns, and a conversation-level drill-down into a single view, giving stakeholders immediate visibility into agent performance without any configuration. Use it as the starting point for daily operational checks or to prepare data for leadership reviews. Navigation: Project → Insights → Dashboard Date range selector: A toggle in the top-right corner lets you select 7d, 30d (default), or 90d. Changing the range refreshes all KPI cards, charts, and conversation data on the page.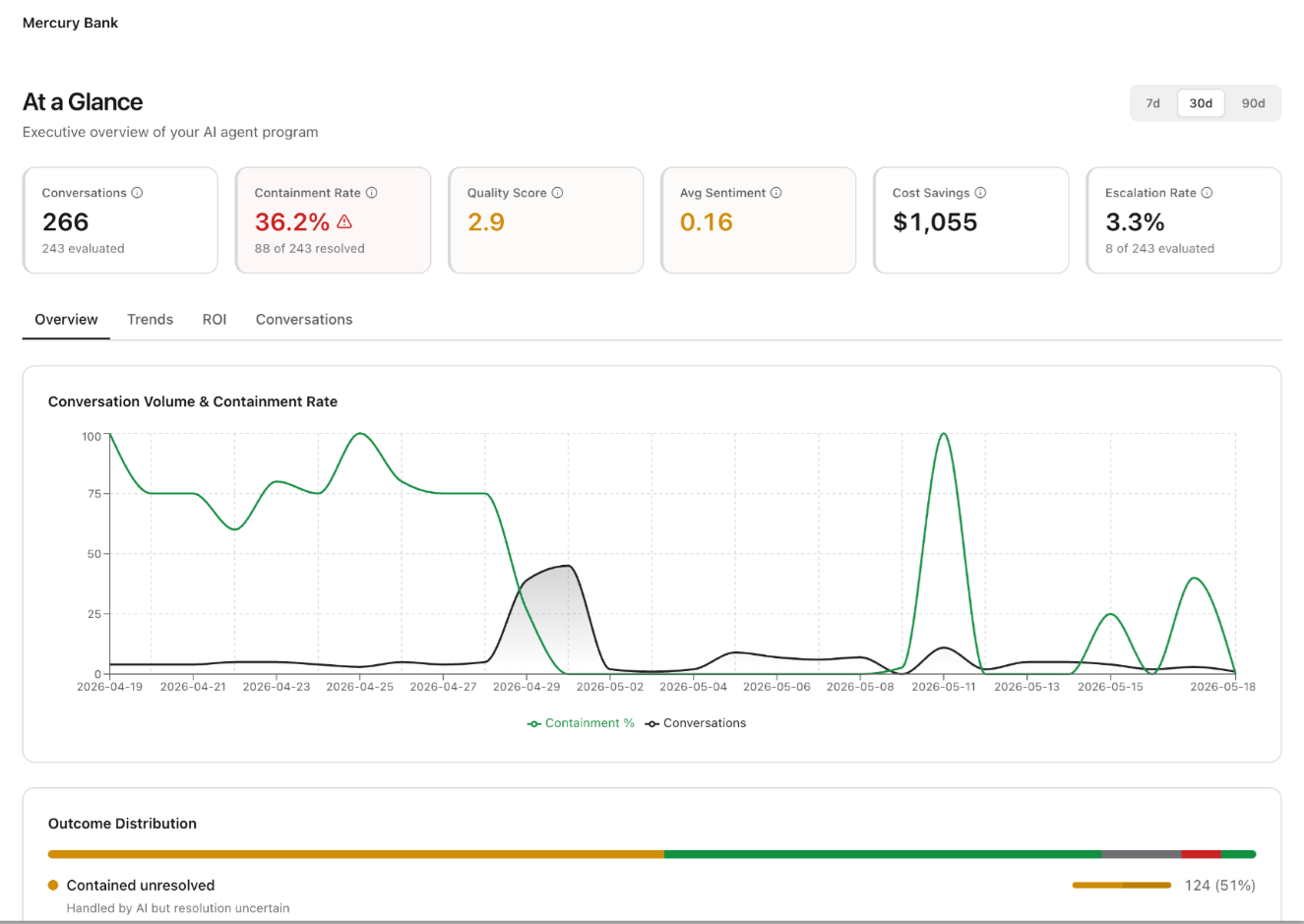
KPI Metric Cards
Six metric cards appear at the top of the page. Each card displays a primary value and, where applicable, a sub-label with supporting context. Warning icons appear on cards where the metric falls below expected thresholds.Views
Below the KPI cards, four views organize the dashboard’s detailed data:Analytics
The Analytics page monitors event volume, LLM performance, token consumption, and cost in near real time. Unlike the Dashboard, it offers granular time controls down to 30-minute windows — useful for investigating production incidents, tracking the impact of model changes, or auditing LLM spend during peak traffic. Navigation: Project → Insights → Analytics Time range controls: Analytics supports the most granular time ranges in the Insights section: 30m, 1h, 3h, 6h, 12h, 24h, 2d, 7d, 30d, or a Custom range where you specify exact start and end timestamps. This granularity is especially useful for correlating agent errors or latency spikes with specific deployment events.