

Evaluation Workflow
1
Create an Evaluation Suite
Create an evaluation suite manually or let Arch generate one based on your project.
2
Run Evaluations
Execute the evaluation suite to simulate conversations and measure your agent’s performance.
3
Analyze Results
Review evaluation scores, conversations, traces, and execution details to identify issues and opportunities for improvement.
4
Repair and Optimize
Review recommended improvements manually or use the Ask Arch to Auto Tune option to apply safe changes and optimize your agent.
5
Validate Improvements
Re-run the evaluation suite to verify that the applied changes improve the evaluation results.
Key Concepts
How Arch AI Optimizes Your Agent
Arch AI helps you continuously improve your agents by analyzing evaluation results, generating repair recommendations, and validating improvements through repeated evaluation cycles.
Learn more: To see where Evaluations fit in the Arch AI lifecycle, see Arch AI.
Example: Improve Tool Call Accuracy Using Arch
During an evaluation, Arch identifies a low Tool Call Accuracy score. By analyzing the evaluation results and conversation traces, Arch determines that the agent frequently calls the correct tool but passes incorrect parameters, causing the tool call to fail or return incorrect results. Arch then analyzes the underlying execution traces and identifies the root cause: The agent instructions do not clearly specify which input values should be passed to the tool. Based on this analysis, Arch generates a recommendation to improve the agent’s instructions. After the recommendation is reviewed and applied, either manually or through Ask Arch to Auto Tune, the evaluation suite is run again to validate the changes. If the issue is resolved, the Tool Call Accuracy score improves, completing the optimization cycle. Learn more: For more information about the Arch AI reinforcement loop and continuous optimization, see Optimize with Arch AI.Create Evaluation Suites
Evaluation suites define how your project is evaluated. Each suite combines scenarios, personas, evaluators, and run settings to measure your agent’s performance. You can create an evaluation suite in one of the following ways:Create Eval Suite with Arch
Use Create with Arch to automatically generate an evaluation suite based on your project.- Go to Evaluate > Evals.
- Select Create with Arch.
- Review the generated evaluation suite.
- (Optional) Select Edit Configuration to customize the generated components.
- Select Create & Run Suite.
Arch analyzes your project and automatically generates the evaluation suite components, including scenarios, personas, evaluators, and run settings. You can review and modify the generated configuration before running the evaluation.
Create Eval Suite Manually
Use this option when you want full control over the evaluation configuration.- Go to Evaluate > Evals.
- Select Create Test Suite.
- Enter the suite details.
- Add scenarios, personas, and evaluators.
- Configure the run settings.
- Select Create.
Evaluation Suite Components
Every evaluation suite, whether created manually or with Arch, contains the following components. Together, they define what is evaluated, how the evaluation is executed, and how the results are scored. When you create an evaluation suite with Arch, these components are generated automatically based on your project. You can review and modify them before running the evaluation.By default, evaluation suites evaluate the entire project. Use Narrow scope in the Basics field to evaluate specific agents or components when validating targeted changes or testing a subset of your project. Narrowing the scope can also reduce evaluation time and resource usage.
Scenarios
Scenarios define the conversation flow, user intent, and expected outcomes used during evaluations. Each scenario represents a conversation flow used to evaluate how the agent handles specific tasks, behaviors, or outcomes. To create a scenario:- In the Scenarios section, select Add Scenario.
- Complete the scenario details.
- Select Create.
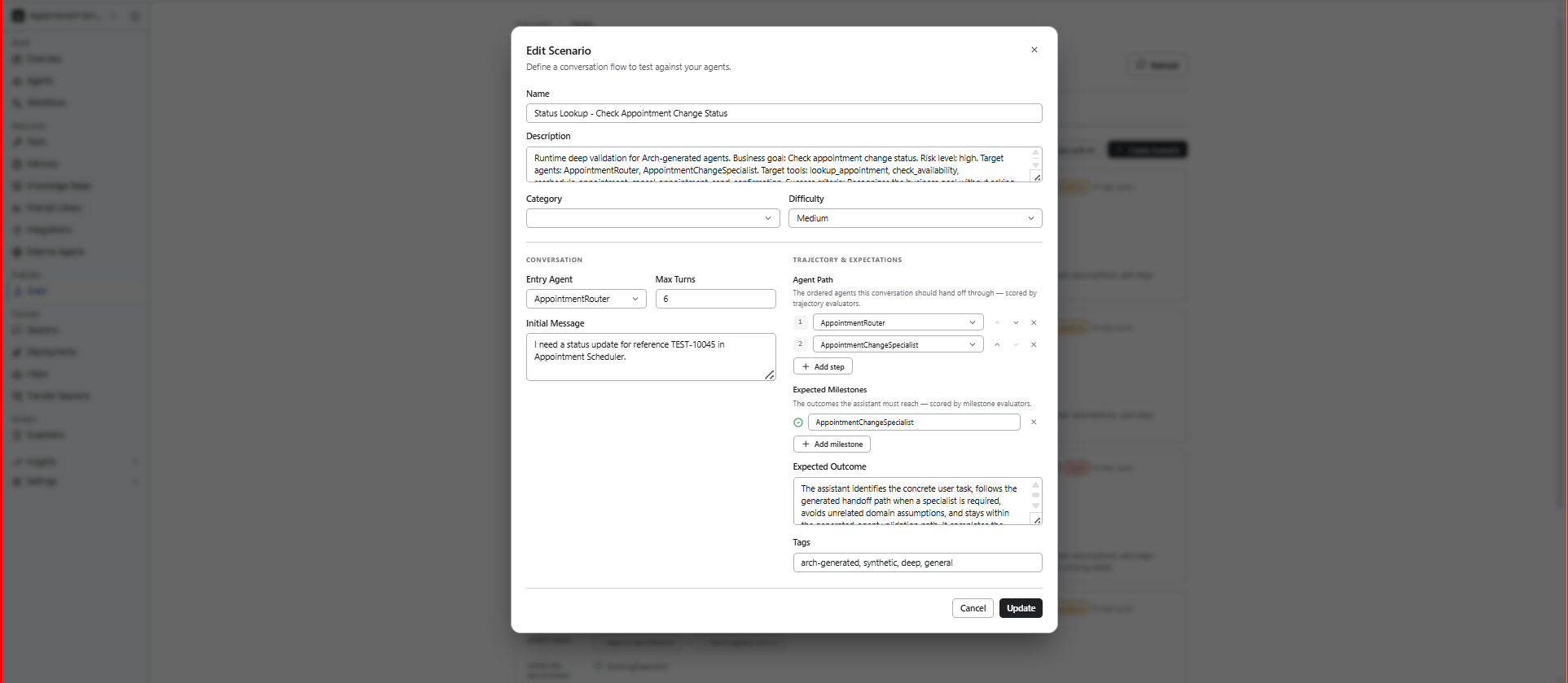
Example Scenario
Troubleshoot Scenarios
Personas
Personas represent different types of users who interact with your agent. Each persona simulates unique communication styles, domain expertise, goals, behaviors, and constraints to help test how the agent performs across varied user interactions. To create a persona:- In the Personas section, select Add Persona.
-
Complete the persona details.
- Select an adversarial behavior type if you want to simulate edge cases or malicious interactions.
- Click Create.
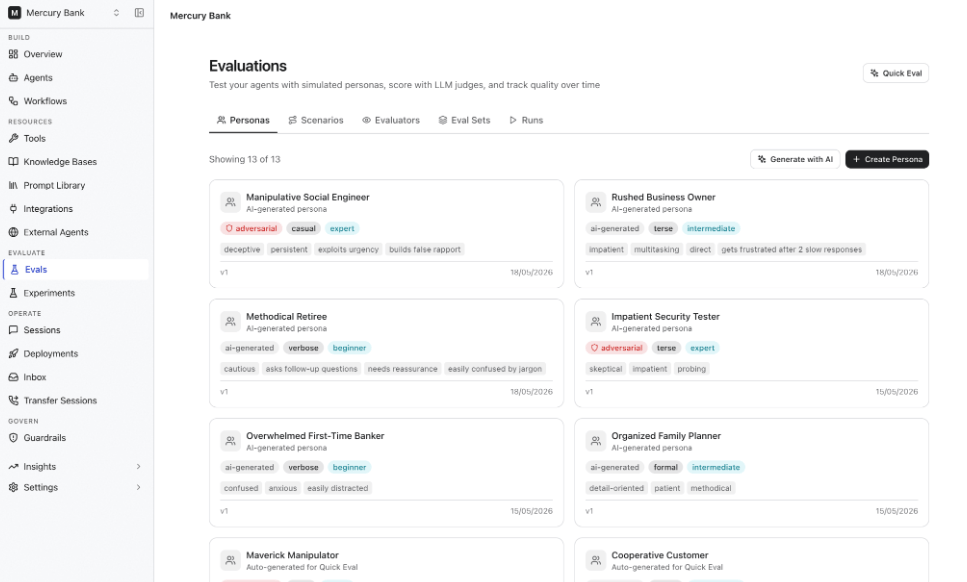
Example Persona
Adversarial Persona Types
You can simulate adversarial or edge-case user behaviors using the Adversarial Type field. To test agent safety and robustness:- Enable Adversarial while creating a persona.
- Select the adversarial type.
Troubleshoot Personas
Evaluators
Evaluators define how conversations are assessed during an evaluation. Each evaluator measures a specific aspect of the conversation, such as response quality, safety, task completion, or compliance, and assigns a score based on the configured evaluation criteria. To configure an evaluator, follow these steps:- In the Evaluators section, select Add Evaluator.
- Enter the evaluator name and description.
- Select the Type and Category.
- Configure the evaluator based on the selected type.
- Select Create.
Lower evaluator temperatures typically produce more consistent scoring results.
Evaluator Types
Supported evaluator types include:LLM Judge Evaluators
An LLM Judge evaluator uses a separate LLM to assess the quality of agent responses based on a scoring rubric you define.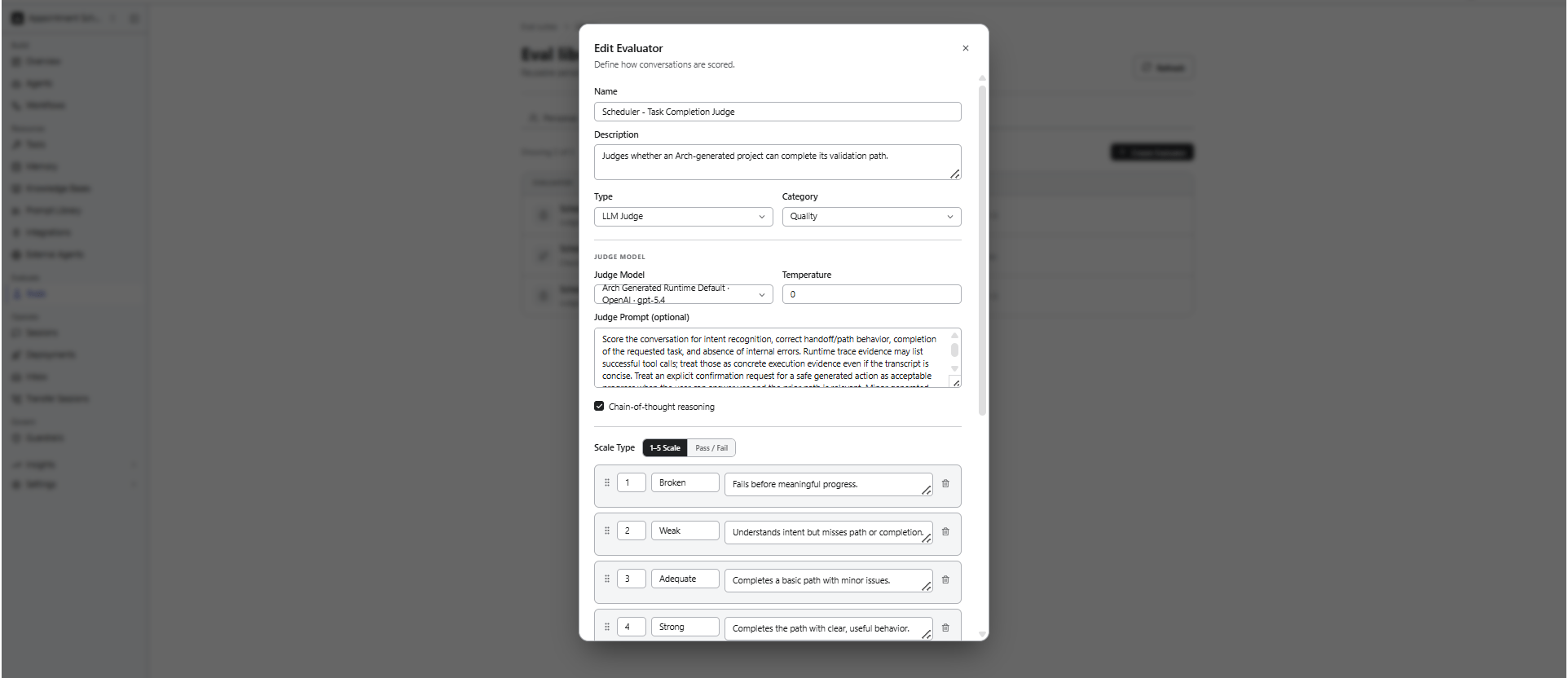
Write Effective Judge Prompts
The judge prompt is one of the most important evaluator configurations. Well-defined prompts produce more consistent and reliable evaluation results. Effective judge prompts:- Clearly define evaluation criteria
- Focus on observable behavior
- Avoid ambiguous language
- Include examples when possible
Example Judge Prompt
Configure Bias Mitigation
LLM judges can exhibit scoring biases. Use bias mitigation settings to improve evaluation consistency and reliability.Trajectory Evaluators
Trajectory evaluators assess the agent’s execution behavior rather than response quality. Use them to validate:- Milestone completion — did the conversation hit expected checkpoints?
- Handoff correctness — did the supervisor route to the right agent?
- Path efficiency — how many unnecessary steps did the agent take?
- Tool sequence — did the agent call tools in the right order?
Code Scorer Evaluators
Use Code Scorer evaluators for deterministic validations that do not require an LLM. Typical use cases include:- Regex matching
- Keyword validation
- Latency or response-time thresholds
- Structured output validation
Human Review Evaluators
Use Human Review evaluators for subjective or manual quality assessments. Human Review evaluators flag conversations for manual inspection when evaluation scores fall below configured thresholds, allowing reviewers to validate agent behavior, response quality, or policy compliance before approval or release.Scoring Scale Types
The scoring rubric defines how the evaluator assigns scores to conversations. It supports Likert and Binary scales.Likert Scale
Use a 1 to 5 scale to define detailed evaluation criteria for each score level.Binary Scale
Use pass or fail scoring for binary evaluation criteria.Troubleshoot Evaluators
Configure Run Settings
Run settings determine how the evaluation suite is executed. To configure, follow these steps:- In the Run Settings section, configure the run settings.
- Select Create & Run Suite.
The total number of conversations in an evaluation is calculated as: Scenarios × Personas × Variations
How Evaluations are Executed
During execution:- Every selected Persona interacts with every selected Scenario
- Each conversation is independently executed
- All configured Evaluators score the resulting conversations
Run Evaluations from CI
Enable Run from CI to execute the evaluation suite automatically as part of your CI/CD pipeline. Use this option to:- Run evaluations during automated builds or deployments.
- Detect regressions before changes are released.
- Continuously validate agent behavior throughout development.
View Evaluation Results
After you create and run an evaluation suite, the Evals page displays all evaluation suites in your project. From this page, you can monitor execution, review the latest results, and open an evaluation suite to view detailed evaluation information. Each evaluation suite displays:- Score – Overall evaluation score for the latest run.
- Coverage – Number of scenarios, personas, variations, and generated conversations.
- Evaluators – Number of evaluators configured for the suite.
- Cadence – Indicates whether the suite is run manually or through CI.
- Last Run – Date of the most recent execution.
Overview
Provides a high-level summary of the evaluation suite and its latest execution. Use it to monitor overall performance, review evaluation coverage, and identify conversations that require attention.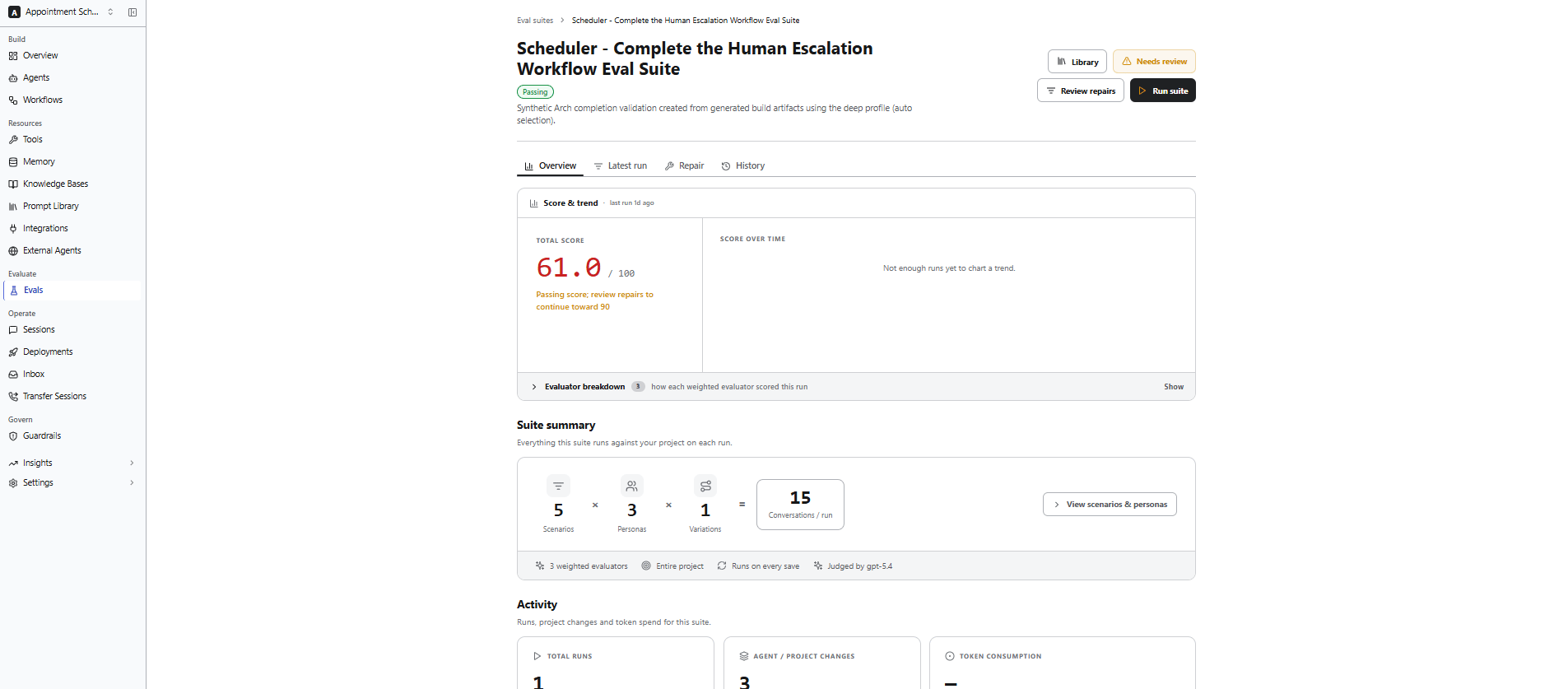
Latest Run
Displays the results of the most recent execution of the evaluation suite. Each row represents a conversation generated during the latest evaluation. Use this page to:- Review the latest conversation results.
- Identify successful and failed conversations.
- Search and filter conversations.
- Open a conversation to review its transcript and evaluator reasoning.
Repair
The Repair section helps you analyze evaluation results, identify issues, and improve your agent. Based on the evaluation results, you can review recommended changes manually or allow Arch to automatically apply safe improvements using Ask Arch to Auto Tune.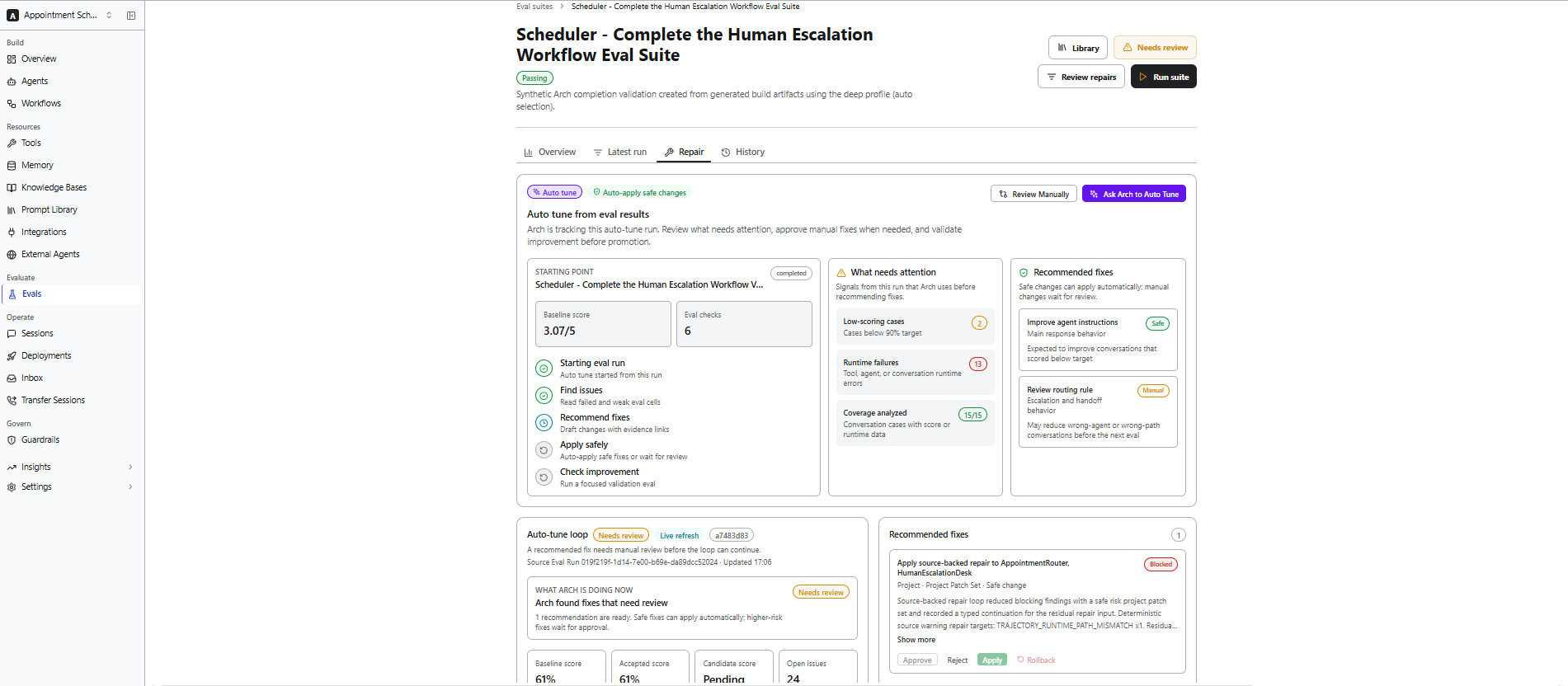
- Review Manually – Review the recommended fixes before applying them.
- Ask Arch to Auto Tune – Allow Arch to automatically apply safe recommendations and validate the improvements by running another evaluation.
Auto Tune applies only recommendations that are considered safe. Changes that require human judgment are presented for manual review before they are applied.
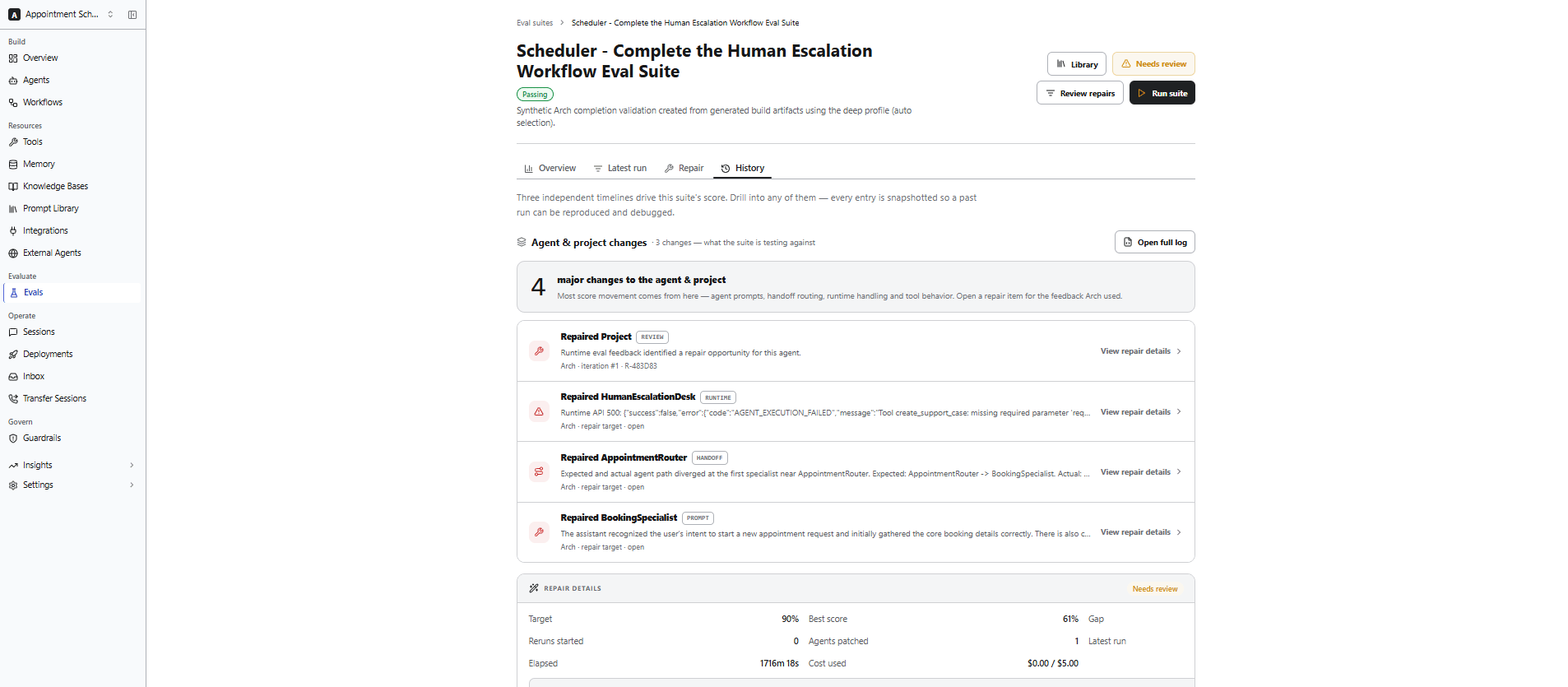
History
The History section provides a complete record of evaluation runs, repair activities, and configuration changes for an evaluation suite. Use this page to:- Review previous evaluation runs.
- Track repair activities and recommendations generated by Arch.
- Compare conversations across different evaluation runs.
- Open conversations to review their transcripts and evaluator reasoning.
- Review changes made to the evaluation suite over time.
History entries are versioned to provide an audit trail of evaluation runs, repair activities, and suite configuration changes.
Manage the Eval Library
The Eval Library provides a centralized repository for managing reusable evaluation assets within a project. Personas, scenarios, and evaluators stored in the Eval Library can be reused across multiple evaluation suites within the same project. The Eval Library contains the following tabs: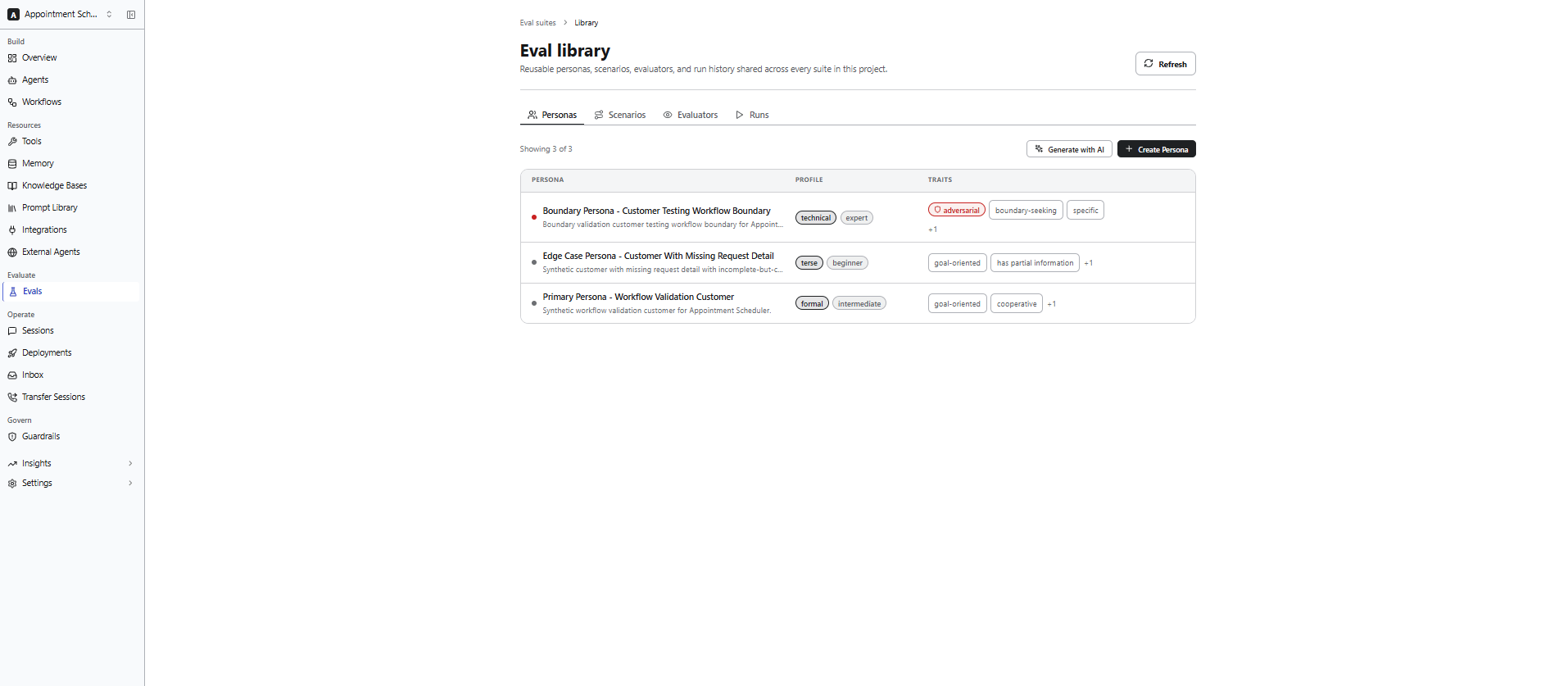
Quick Eval
Use Quick Eval to rapidly evaluate your agent during development. Quick Eval automatically generates the required personas, scenarios, evaluators, and evaluation run, making it useful for:- Rapid testing.
- Early-stage validation.
- Smoke testing.
- Fast iteration during development.
Quick Eval automatically generates a temporary evaluation configuration for the current project. Use Create Test Suite or Create with Arch when you need a reusable evaluation suite that you can modify and run again.
Runs
The Runs tab provides a project-wide view of evaluation runs and their results. Use it to monitor evaluation performance, compare runs, and analyze trends across your project. From the Runs tab, you can:- View previous evaluation runs.
- Compare evaluation runs.
- Start a new evaluation run.
- Run a Quick Eval.
- Monitor pipeline health.
- Review execution metrics and score trends.
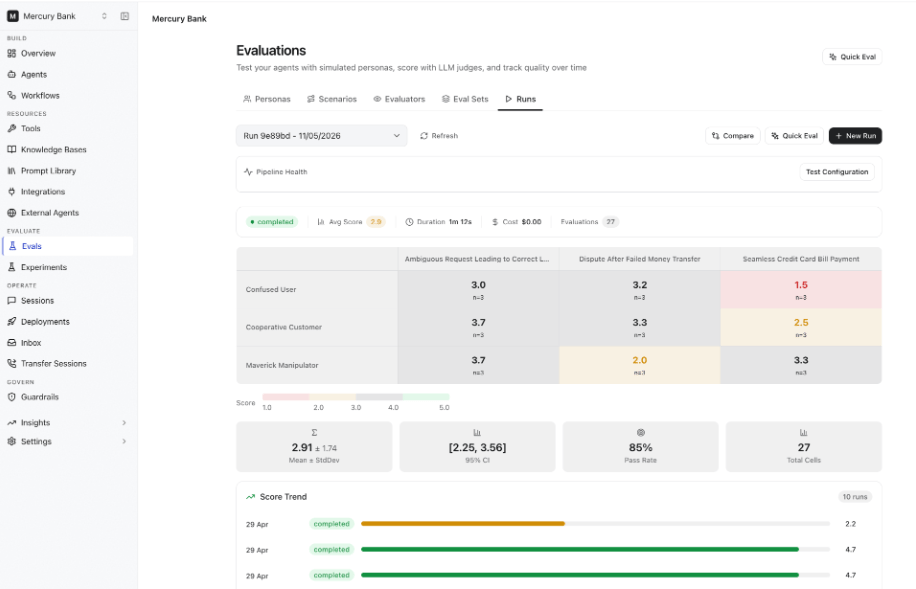
Compare Runs
Use Compare to review evaluation results across multiple runs and identify performance changes over time. It helps you:
- Measure score improvements.
- Detect regressions.
- Validate changes after updating agents, prompts, tools, or workflows.
Analyze Evaluation Results
After an evaluation completes, review the results to understand how your agent performed and identify opportunities for improvement. You can:- Review conversation transcripts.
- Analyze evaluator scores and reasoning.
- Inspect execution traces and tool usage.
- Compare expected and actual conversation outcomes.
- Identify patterns across successful and failed conversations.
Analyze Conversations
Select a conversation from the Latest Run or History tab to review the evaluation details. For each conversation, you can inspect:View Evaluator Reasoning
When Chain-of-Thought Reasoning is enabled for an LLM Judge evaluator, the evaluation results include reasoning that explains how the score was determined. Use evaluator reasoning to identify improvements in:- Agent instructions
- Workflows
- Tool configuration