AI-Assisted Manual Audit enables supervisors and QA teams to evaluate voice and chat interactions using a hybrid workflow that combines AI-generated insights with manual scoring in a single workspace. The workspace provides transcripts, interaction metadata, timeline navigation, AI-generated summaries, topics, sentiment, resolution status, evaluation metrics, and scorecards to support consistent quality assessments. Evaluators can review AI recommendations, confirm or override scores, add comments, and submit final audit results for coaching and compliance.
When Agent Accept & Dispute is enabled, agents can use the audit workspace to review evaluation results, acknowledge scores, and dispute individual metrics. Supervisors can then review each disputed metric and complete the re-evaluation workflow.
When Scheduled Processing is enabled for supported conversation sources (Agent AI, CCAI, and Automation AI), conversations become available in AI-Assisted Manual Audit immediately after they end, even before Quality AI processing begins. Until processing completes, only conversation metadata is available. AI-generated insights, transcript analysis, evaluation metrics, and scoring appear after processing is complete.
Note: When Scheduled Processing is enabled, supervisors can open Pending and Validation Failed conversations directly from Conversation Mining before Quality AI processing completes.
| Capability | Description |
|---|
| AI Summary and Insights | Displays AI-generated summaries, topics, sentiment, resolution status, and interaction metrics. |
| Multi-language Support | Supports auditing across configured languages. |
| Topics & Intents | Identifies customer purpose and discussion themes. |
| Sentiment and Emotion Analysis | Tracks customer and agent sentiment and emotion trends throughout the interaction. |
| Automated QA Scoring | Uses AI to evaluate configured metrics and generate Auto QA scores. |
| Agent Dispute and Acknowledgment | Agents review metric-level scores, accept aligned outcomes, and dispute scores with supporting comments. Supervisors re-evaluate disputes with a written response per metric. |
| Audit Logs | Tracks audit activity, AI execution details, and evaluation history. |
| Audit Trail | Chronological log of every evaluation action from creation through to resolution, across all dispute rounds. |
| Timeline and Keyword Navigation | Provides keyword highlighting and timeline markers for faster navigation. |
| Comments and Feedback | Supports message-level and metric-level comments with transcript navigation. |
| Direction-Aware Evaluation | Applies evaluation forms based on inbound or outbound interaction direction. |
| Duration Handling | Excludes short interactions from Auto QA scoring while supporting manual audit. |
| Hold and Transfer Evaluation | Evaluates hold etiquette, transfer handling, silence, and cross-talk behavior. |
| Manual Evaluation | Enables evaluators to review and override AI-generated results using Yes, No, or N/A scoring. |
| Mark for Coaching | QA Users can flag agents for coaching directly from the Audit Screen and manage coaching groups without leaving the review workflow. |
Prerequisites
Before using AI-Assisted Manual Audit, confirm the following:
- Auto QA Permission: Access to manage metric types in Quality AI General Settings.
- QA Access: Permission to perform self-assignment and auditing.
- Role-Based Access: Appropriate permissions assigned based on your organizational role.
- GenAI Settings: Enable sentiment, emotions, and topic modeling features as required.
- Metric Settings: Enable Speech, Playbook, Hold Etiquette, and related metrics when needed.
- Agent Dispute: Enable Agent Accept & Dispute in Quality AI > Settings > Quality AI General Settings to activate the metric-level dispute and acknowledgment workflow.
Access AI-Assisted Manual Audit
Navigate to Quality AI > Conversation Mining > Interactions > AI-Assisted Manual Audit.
 You can open interactions from:
You can open interactions from:
- Conversation Mining: View all conversations within your assigned queues.
- Allocations: View all evaluated interactions along with their current review and dispute status.
- Allocations > Disputes: View disputed interactions routed to you for re-evaluation.
- Review > Pending Review, Disputes, or Resolved (agent view): View evaluations pending a response or active disputes.
Audit Workflow
- Select an interaction.
- Review transcript, timeline, and AI insights.
- Select Assign to Me if the interaction isn’t assigned.
- Complete all required metrics.
- Add comments if needed.
- Select Mark for Coaching to flag the agent for coaching review.
- Select Submit to complete the audit. If you configure disputes in the evaluation form, the system shows the completed evaluation to the agent for acknowledgment or dispute.
The header identifies the conversation, current audit stage, and available workflow actions.
| Element | Description |
|---|
| Agent Name | Shows the name of the agent whose conversation is under evaluation. |
| Date and Time | Shows when the interaction occurred. |
| Audit Review Label | Shows the current audit stage. See Audit Review Labels. |
| Review Status Badge | Shows the current workflow state (for example, Assigned, Pending Agent Review, Pending Supervisor Review). |
| Mark for Coaching | Flags the evaluation for coaching and follow-up. |
| Cancel | Discards unsaved changes. |
| Submit | Saves the evaluation or re-evaluation and routes it according to the configured workflow. |
Audit Review Tabs
The system displays Audit Review statuses based on the selected Allocations tab and audit workflow stage, helping you track review progress from Assigned through Pending Supervisor Review, Resolved, and Closed.
| Label | Description | What It Shows |
|---|
| Unassigned | Shows that no auditor or reviewer has claimed the interaction for review. | Displays interactions that are available for assignment and aren’t assigned to any agent. |
| Assigned | Shows that the system assigns the audit review to the current auditor or reviewer. | Audit Review → Assigned to Me (audit assigned to you for review). |
| Pending Agent Review | Shows that the audited agent must review the evaluation, acknowledge it, or respond before the workflow can continue. | Audit Review → My Evaluations (awaiting the agent’s review, acknowledgement, or response). |
| Pending Supervisor Review | Shows that a supervisor must review and decide on the audit or dispute. | Audit Review → My Evaluations, Audit Review → Disputes (awaiting supervisor review and decision). |
| Resolved | Shows that the reviewer or supervisor completed the review process and reached a resolution. | Audit Review → My Evaluations (after resolution). |
| Closed | Shows that the system completed the audit review workflow and no further action is available. | The system finalizes the audit review and prevents further actions. |
Processing Status
Processing Status indicates whether Quality AI has completed conversation processing.
| Status | Description |
|---|
| Processed | Quality AI completed conversation processing. All audit insights and evaluation data are available. |
| Pending | The conversation is waiting for processing. Only conversation metadata is available. |
| Validation Failed | Quality AI could not process the conversation because validation failed. Conversation metadata remains available, but AI-generated analysis and evaluation data are unavailable. |
Audit Screen Tabs
The Audit Screen provides role-based access to evaluation, transcript review, audit history, and dispute management.
| Tab | Who Sees It | Description |
|---|
| Audit | Supervisor, Agent | Supports transcript review, scoring, AI insights, and dispute responses. |
| Conversation Details | Supervisor, Agent | Shows interaction metadata, channel, direction, scores, identifiers, and custom fields. |
| Audit Logs | Supervisor, Agent | Records audit history, user actions, and AI execution logs. |
| Audit Trail | Supervisor only | Records all evaluation actions from creation to resolution. |
| Audit Review | Supervisor, Agent | Shows audit stage, workflow status, and dispute handling actions. |
Audit Tab
The Audit tab combines transcript review, AI analysis, scoring, dispute handling, and coaching workflows.
| Section | Description |
|---|
| Transcript and Timeline (Left) | Displays timestamps, speaker labels, highlights, comments, and synchronized playback for voice interactions. |
| AI Insights or Metrics Panel (Right) | Shows evaluation metrics, AI-generated scores, adherence status (Yes/No/N/A), manual scoring, and dispute threads for each metric. |
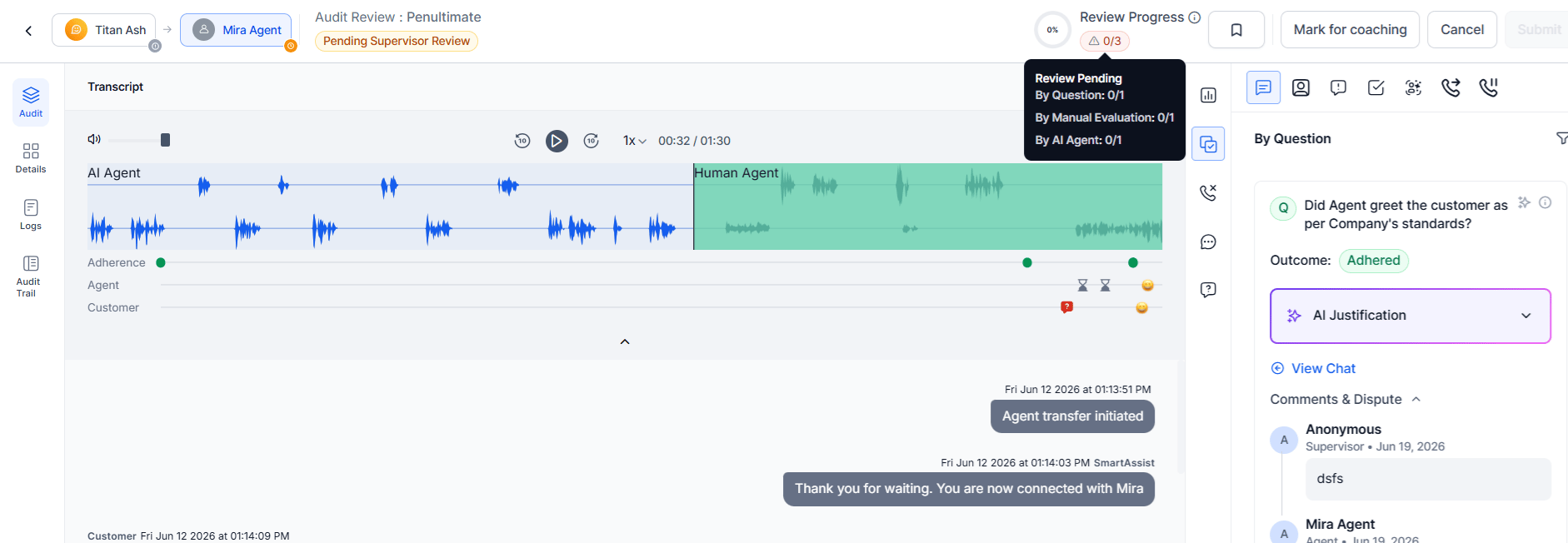
Audit Progress
The audit progress bar at the top of the metrics panel tracks evaluation completion across all scoring sources. Its status varies by Allocation tab and audit workflow stage.
| Element | Description |
|---|
| Audit Progress Indicator (Percentage + Bar) | Shows overall audit completion as a percentage and progress bar based on completed out of total configured metrics (for example, 0% • 0/24). |
| Audit Progress Tooltip | Shows a breakdown of completion by evaluation source, such as Question, Speech, Playback, Value, AI Agent, Transfer, Hold, and Manual. Displays values as Completed/Total for each source. |
| Audit Count | Shows completed evaluations out of total configured evaluations across all scoring sources. |
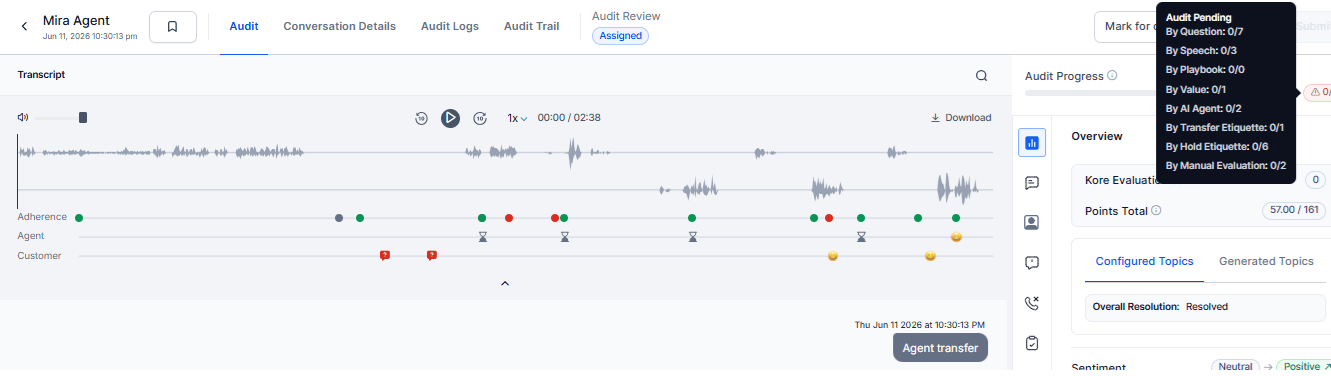
Note: The tooltip displays only configured evaluation sources. The progress indicator updates automatically as users complete metrics. The Submit button remains disabled until all required metrics are completed.
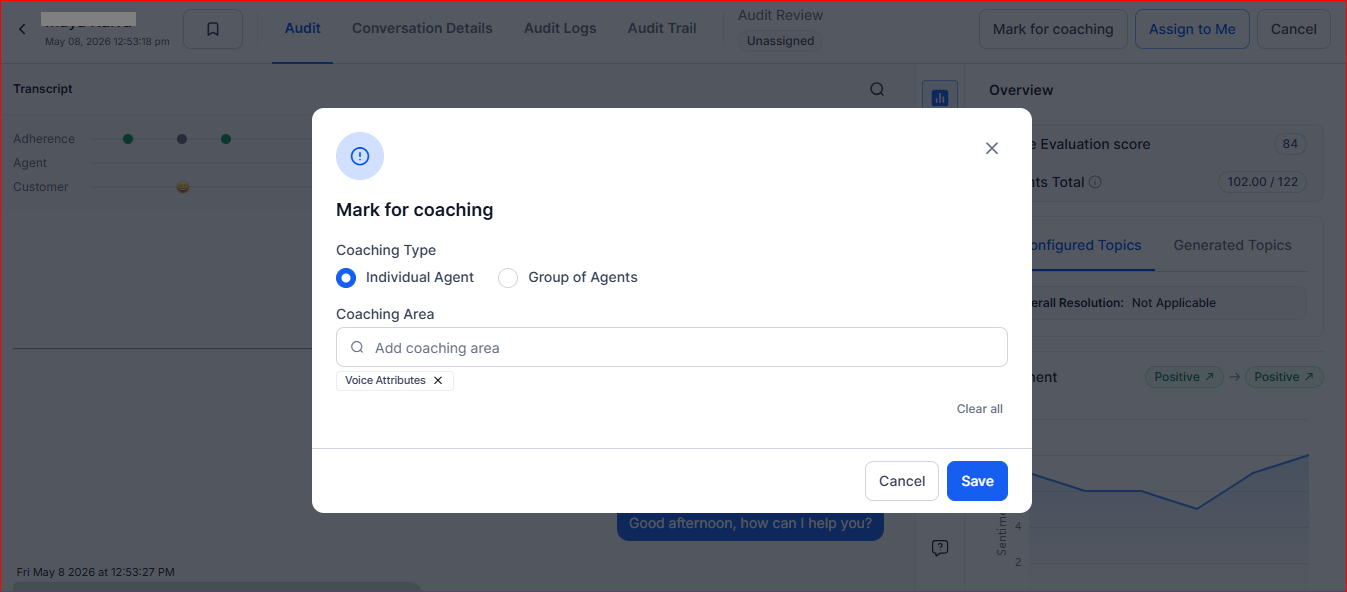
Mark for Coaching
The Audit screen includes a Mark for Coaching action that enables QA users to create coaching recommendations directly from an audit. Only users with the required QA permissions can access this action.
Individual Agent Coaching
Select Individual Agent to create a coaching recommendation for the agent associated with the audited interaction.
| Field | Description |
|---|
| Coaching Method | Select the coaching framework or template to use. |
| Coaching Area | Select one or more coaching areas identified during the audit. |
Group of Agents Coaching
Select Group of Agents to create a coaching recommendation for a predefined coaching group.
| Field | Description |
|---|
| Coaching Method | Select the coaching framework or template to use. |
| Group | Select an existing coaching group. |
| Add New Group | Create a new coaching group if a suitable group doesn’t exist. |
Add New Group
Select + Add New Group to create a coaching group.
| Field | Description |
|---|
| Group Name | Enter a unique name for the coaching group. |
| Description | Enter additional information about the group’s purpose or objectives. |
| Coaching Method | Select the coaching method associated with the group. |
| Coaching Area | Select the category of coaching metrics to associate with the group (for example, Agent Attribute). |
| Search Agent Attribute to Add | Search and select agent attributes to include in the group. |
| Assigned Agent Attributes | Displays selected attributes. Shows No Agent Attribute Added if empty. |
Coaching Recommendation Creation
When a QA user saves a coaching recommendation:
- The system creates a coaching recommendation based on the selected coaching type.
- The system associates the recommendation with the audited interaction and selected coaching areas.
- The system assigns the recommendation to the selected coaching group.
- The coaching recommendation becomes available for subsequent coaching activities and tracking.
Available coaching methods, groups, and coaching areas depend on the coaching configurations defined in the system.
Supervisor View — Review Panel
The review panel on the right displays evaluation metrics, reviewer responses, comments, and dispute history. Supervisors can review disputed metrics, update responses, and resolve disputes.
| Element | Description |
|---|
| Review Progress | Displays the percentage of completed metric evaluations and the number of completed metrics out of the total configured metrics. |
| Metric Group | Displays metrics grouped by evaluation category, such as By Manual Evaluation. |
| Metric Count | Displays the number of metrics within the selected evaluation category. |
| Metric Question | Displays the evaluation question under review. |
| Response Options | Enables the supervisor to select the evaluation outcome, such as Yes, No, or N/A. |
| Filter | Filters metrics within the selected evaluation category. |
| Comments & Dispute | Displays comments, dispute history, and responses associated with the metric. |
| User Timeline | Displays comments with the contributor name, role, and timestamp. |
| Accept | Accepts the dispute or updated response and finalizes the decision for the metric. |
| Deny | Rejects the dispute and retains the existing evaluation outcome. |
| Status Indicator | Displays the current status of the metric, such as Agent Accepted. |
| Element | Description |
|---|
| Reviewer Comment | Displays comments added by a supervisor or QA reviewer. |
| Agent Comment | Displays comments submitted by the agent during review or dispute. |
| User Information | Displays the contributor’s name, role, and timestamp. |
| Status Update | Displays metric-level actions such as Agent Accepted. |
Dispute Resolution
When a metric dispute occurs, the system helps supervisors to review the dispute history and take one of the following actions
| Action | Description |
|---|
| Accept | Accepts the agent’s dispute, updates the evaluation outcome if required, and resolves the dispute. |
| Deny | Rejects the agent’s dispute, retains the current evaluation outcome, and resolves the dispute. |
The Comments & Dispute section stores the full review history for each metric, including supervisor comments, agent responses, dispute notes, and resolution status in chronological order.
Agent View — Review Panel
The system enables agents to review evaluation results and respond to metric-level evaluations when dispute functionality is active.
| Element | Description |
|---|
| Metric Question | Displays the evaluation question. |
| Outcome Options | Displays the evaluation result selected by the reviewer. |
| Comments & Dispute | Displays review comments, dispute history, and resolution updates. |
| Accept | Acknowledges the evaluation result. |
| Dispute Comment | Enables the agent to provide justification when disputing a metric. |
| Status Indicator | Displays the current review status, such as Agent Accepted or Disputed, Accepted, or Denied. |
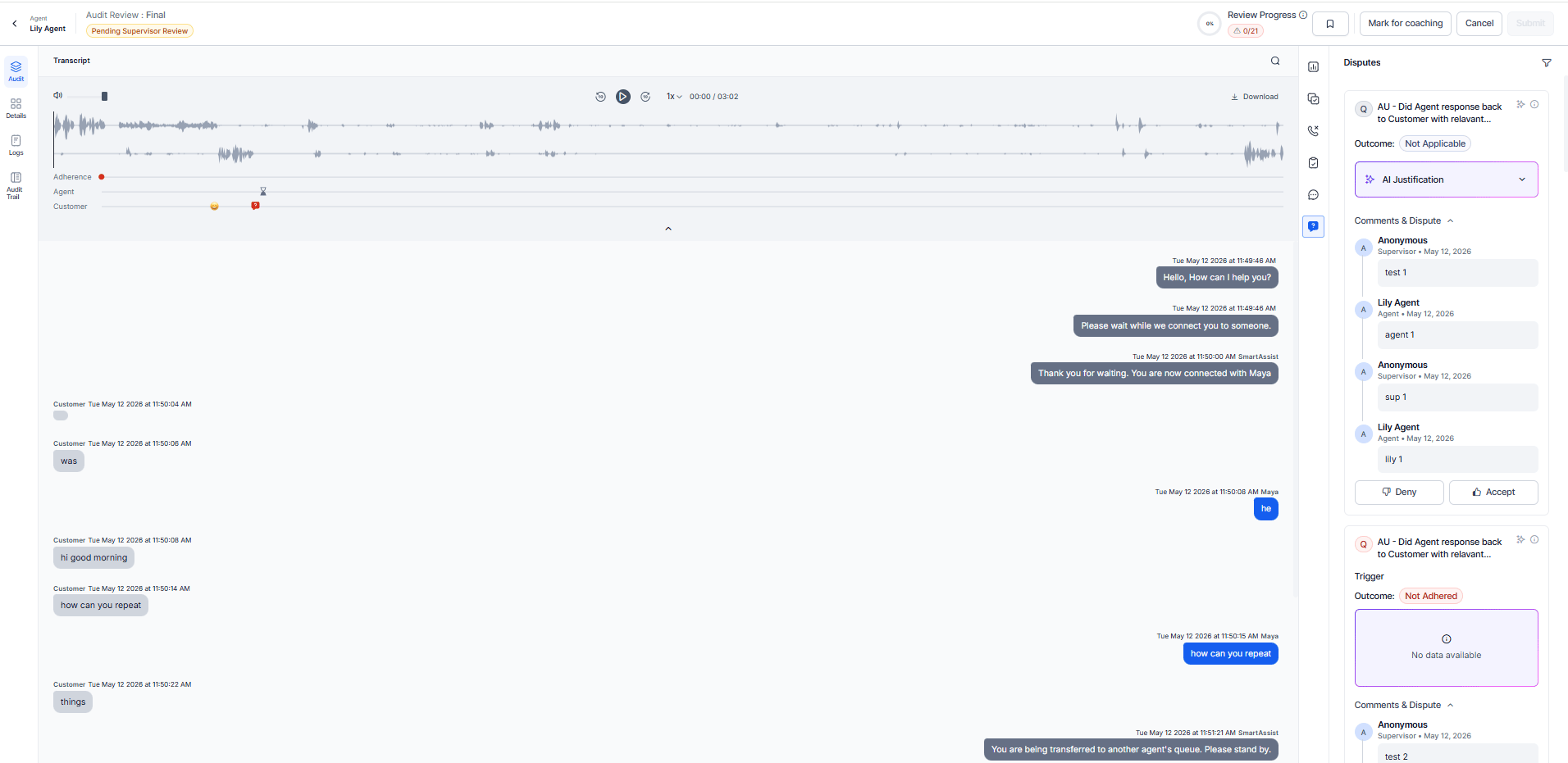
Agents can respond at the metric level instead of the full evaluation. When disputes are enabled, the system requires comments for disputed metrics before submission. When disabled, the system shows the review in read-only mode and disables dispute actions.
Audit Evaluation
AI Overview
Displays conversation insights through AI-powered widgets, helping supervisors evaluate key metrics without reading full transcripts.
This displays high-level evaluation details and scoring:
| Element | Description |
|---|
| Kore Evaluation Score | Displays the Auto QA score for the interaction (before manual evaluation). |
| Points Total | Shows the achieved score out of the maximum possible score (for example, 4.00 / 100). |
| Configured Topics | Lists taxonomy-based topics detected in the interaction. |
| Generated Topics | Displays AI-discovered topics beyond configured taxonomy. |
| Overall Resolution | Indicates resolution status (for example, Resolved or Not Applicable). |
| Sentiment | Displays overall interaction sentiment. Shows No Analysis Found if sentiment is unavailable. |
Score Summary
Displays key behavioral and linguistic metrics:
| Metric | Description |
|---|
| Empathy Score | Measures agent empathy based on conversation analysis. |
| Sentiment Score | Aggregated sentiment score for the interaction. |
| Crutch Word Score | Measures usage of filler words (for example, um, uh). |
NA.
Topics and Intents
| Element | Description |
|---|
| Topics | Identifies key discussion themes using NLP and taxonomy-based classification. |
| Configured Intents | Intents mapped to predefined taxonomy with click-through navigation. |
| Generated Intents | AI-detected intents with sentiment indicators. |
Resolution and Sentiment
| Element | Description |
|---|
| Overall Resolution | Indicates whether the interaction was successfully resolved. |
| Topic Sentiment | Displays sentiment (positive, neutral, negative) for each topic. |
Generated Topics
-
Expands topic discovery beyond configured taxonomy.
-
Provides topic-level sentiment insights.
-
Enhances visibility into conversation patterns.
Transcript and Timeline
The Transcript provides a unified, time-synchronized view of the interaction across chat and voice.
- Speaker-separated conversation (Agent and Customer).
- Timestamped utterances.
- Keyword highlighting and navigation.
- Inline and clickable comments.
- Audio playback with synchronized transcript (voice only).
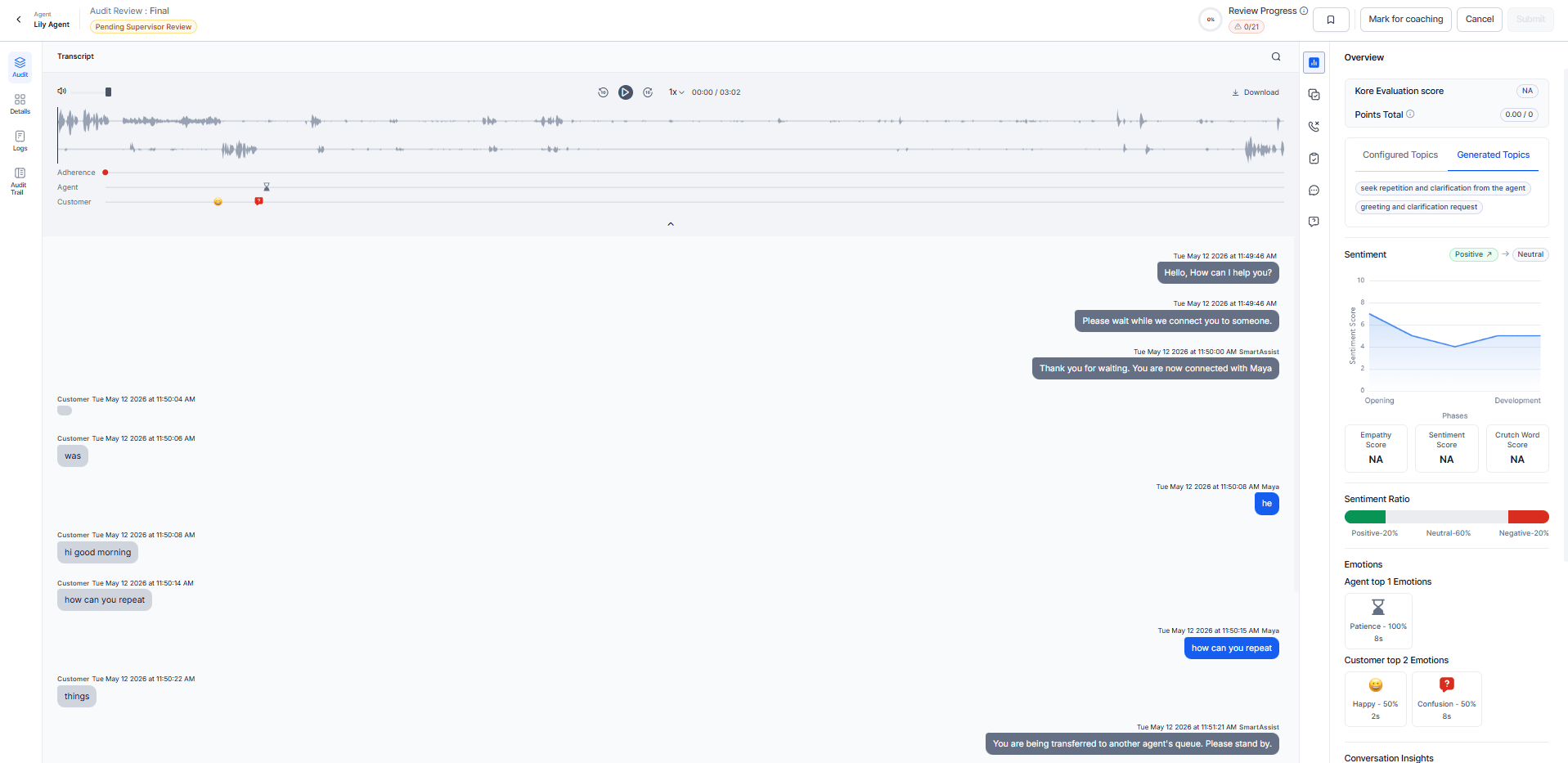
Sentiment Analysis
Shows the overall sentiment of the customer and agent across three phases of the call.
| Phase | Description |
|---|
| Call Opening | From agent transfer to issue identification. |
| Development | From issue identification to resolution discussion. |
| Call Closing | From resolution discussion to call termination. |
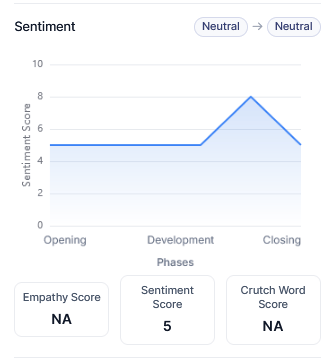
Sentiment Ratio
Displays the distribution of sentiment across the interaction as a percentage breakdown (Positive, Neutral, Negative). If no data is available, it shows No Sentiment Ratio Found.
| Sentiment | Meaning |
|---|
| Positive | Customer satisfaction, successful resolution. |
| Neutral | Standard interaction without strong emotion. |
| Negative | Dissatisfaction or unresolved issues. |
Sentiment Patterns
| Pattern | Meaning |
|---|
| Negative → Positive | Recovery and successful resolution |
| Positive → Positive | Consistent positive experience |
| Neutral → Positive | Improved experience |
| Positive → Negative | Service degradation |
| Neutral → Negative | Missed expectations |
| Negative → Negative | Persistent dissatisfaction |
Emotion Analysis
Tracks emotional signals for both agent and customer across the timeline.
- Agent Emotions: empathy, patience, happiness, frustration, confusion.
- Customer Emotions: satisfaction, anger, confusion, churn risk, escalation.
Rank emotions by duration percentage from highest to lowest and display the top three emotions for each participant using timeline-based visualization and emoticon indicators.
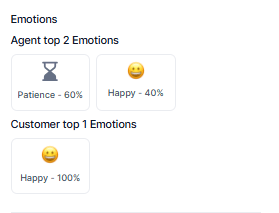
Emotion Analysis
| Section | Description |
|---|
| Agent Top Emotions | Dominant agent emotions |
| Customer Top Emotions | Dominant customer emotions |
Conversation Insights
| Metric | Description |
|---|
| Customer Talk Ratio | % of time customer speaks |
| Agent Talk Ratio | % of time agent speaks |
| Silence | % of inactive time |
Agent Speech Insights
| Metric | Description |
|---|
| Speaking Rate | Words per minute |
| Crutch Words | Filler word count |
| Empathy Score | Speech-based empathy |
Transcript and Timeline
Displays the full interaction with:
- Speaker-separated messages
- Timestamps
- Keyword highlights
- Audio playback (voice only)
- Clickable navigation markers
By Question (Audit)
The By Question section evaluates interactions using configured audit questions through AI-generated analysis and manual validation.
Evaluation Components
| Element | Description |
|---|
| Question Card | Displays the evaluation question. |
| Evaluation Options | Displays Yes, No, or N/A scoring options. |
| Auto QA Result | Displays the AI-generated evaluation result. |
| AI Justification | Displays reasoning and supporting evidence for AI scoring. |
| View Chat | Navigates to the related transcript section. |
| Add Comment | Adds metric-level comments. |
| Audit Progress Bar | Displays audit completion progress. |
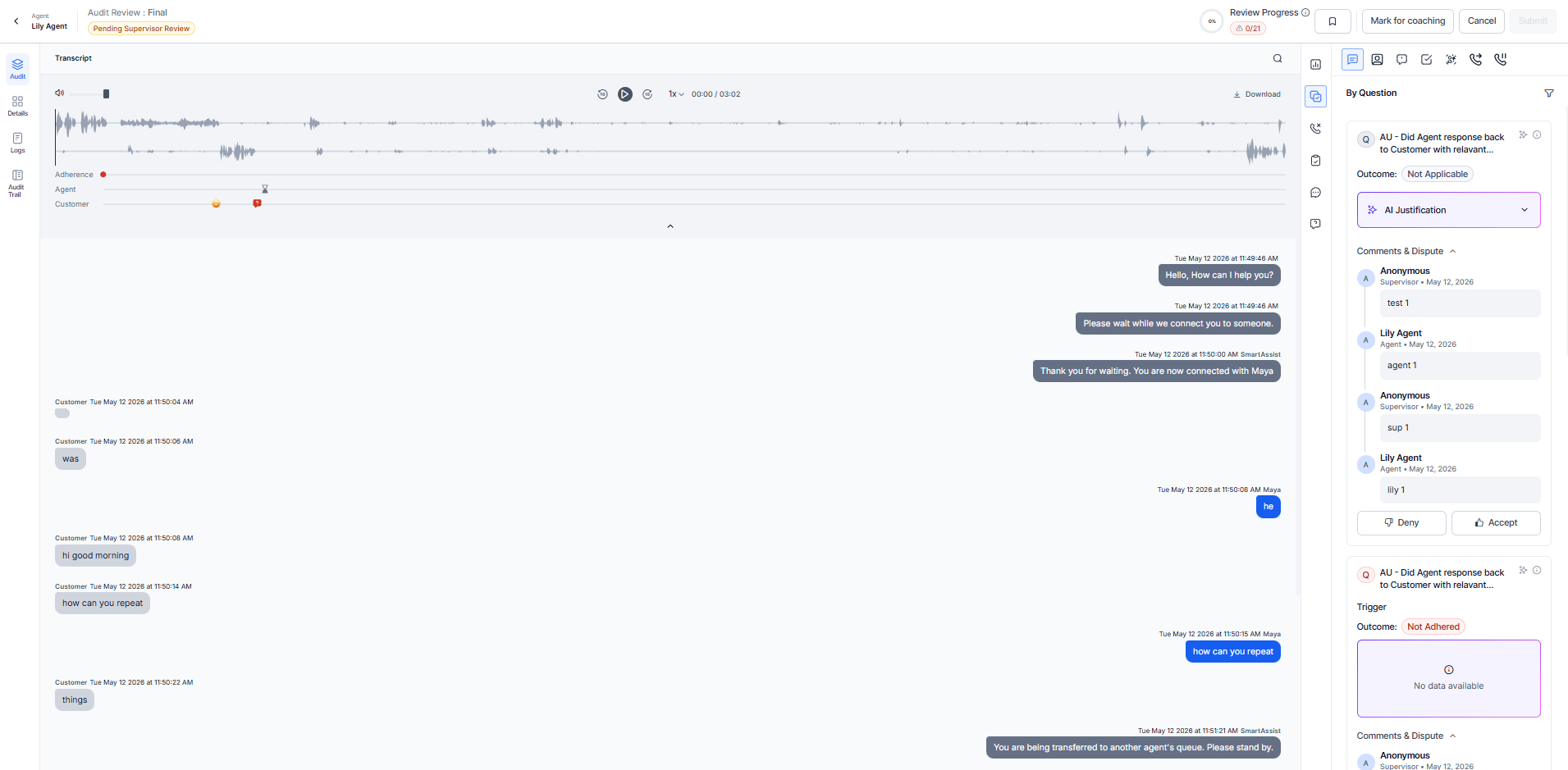
AI Justification
The AI Justification section uses LLM-generated explanations to clarify Auto QA decisions in By Question metrics. It explains Adhered, Not Adhered, and Not Applicable outcomes and improves transparency by showing why a metric passes, fails, or isn’t evaluated.
What AI Justification displays:
| Scenario | What the Justification Shows |
|---|
| Adhered - Yes | The system confirms that the agent met the expected behavior and may include supporting context in its reasoning. |
| Not Adhered (Omission) | The system identifies that the expected behavior isn’t observed across the interaction. The system doesn’t display timestamps because no specific message or event causes the failure. |
| Not Adhered (Violation Event) | The system identifies a specific message or behavior that causes non-adherence. The system includes timestamps only for violation scenarios where a specific conversation event causes the failure (for example, when an agent displays rude behavior). |
| Not Applicable (Dynamic By Question) | The system generates an LLM-based justification explaining why the trigger intent wasn’t detected in the conversation. This displays in the Reasoning section and helps users refine trigger prompts during design time. |
| Outcome | Displays the evaluation result as either adhered or not adhered. The system doesn’t display Not Applicable as a standard outcome; instead, AI Justification handles it for Dynamic By Question metrics. |
| Reasoning | Provides an expandable explanation of the evaluation decision. It explains why the system assigns the outcome, highlights relevant conversation context or missing behavior, and gives evaluation-specific justification instead of a generic summary. |
Dynamic By Question – Not Applicable Justification
For Dynamic By Question metrics, when the system doesn’t detect the trigger intent, it generates an LLM-based justification explaining the absence of relevant conversational evidence and why the intent doesn’t qualify for evaluation. This helps users refine and optimize trigger prompts during design time.
Timestamp Generation Rule
-
Timestamps included: When a specific agent message or event causes a violation (for example, rude or non-compliant behavior).
-
Timestamps not included: For omission scenarios where expected behavior is missing and no specific message or event caused the outcome.
Timestamp Examples
-
Valid (Violation-Based): Professionalism metric → Agent used rude language → timestamps displayed for relevant messages.
-
Invalid (Omission-Based): Greeting metric → Agent doesn’t greet → no timestamps displayed.
Adherence Filter Status
Filter and sort compliance metrics by adherence status:
| Status | Description |
|---|
| Adhered | The response meets the compliance requirement. |
| Not Adhered | The response doesn’t meet the compliance requirement. Display timestamps only for violation scenarios where a specific message or event causes the issue, and don’t display them for omission-based failures. |
| Not Applicable | For static metrics, the metric isn’t relevant to the interaction context. For Dynamic By Question metrics, the trigger intent isn’t detected, and the system provides an LLM-based justification explaining why. |
Audit Navigation and Keyword-based Conversation Analysis
Enables quick filtering and navigation by keyword or QA question, with auto-scrolling of transcripts and relevance-based matching. Keyword filters applied on the Conversation Mining page carry over to the Audit screen.
| Feature | Description |
|---|
| Timeline Integration | Visual markers show exact keyword positions on the timeline. Select a marker to jump to that point in the transcript. |
| Keyword Highlighting | Highlight matched keywords inline using multiple colors and don’t highlight excluded keywords. |
| QA Question Mapping | Keyword matches link to relevant QA questions and their scoring impact in the AI Overview panel, including speaker attribution and count. |
| Context Display | Selecting a keyword expands the surrounding transcript and shows speaker labels, sentiment, and QA impact. |
| Expand or Collapse View | Expand the Keywords Found panel when keyword filters are active and collapse it when no filters aren’t in use. |
| Speaker Filtering | Filter keyword hits by agent or customer. |
| Session Preservation | The system saves keyword filters for the session until you clear them. |
| Clear Filter Keywords | Removes all include or exclude keyword filters from the transcript while keeping other filters unchanged. |
Omissions
Highlights cases where the agent doesn’t follow configured compliance requirements, such as playbook steps or dialog tasks. This includes omitted playbook steps for playbook metrics and omitted dialog tasks for dialog metrics. The system displays only when it has configured relevant metrics for the interaction.
Violations
Highlights speech metric violations that occurred during the call (for example, Cross Talk, Dead Air, or Speaking Rate Violation). Each violation includes a timestamp so you can navigate directly to that point in the recording.
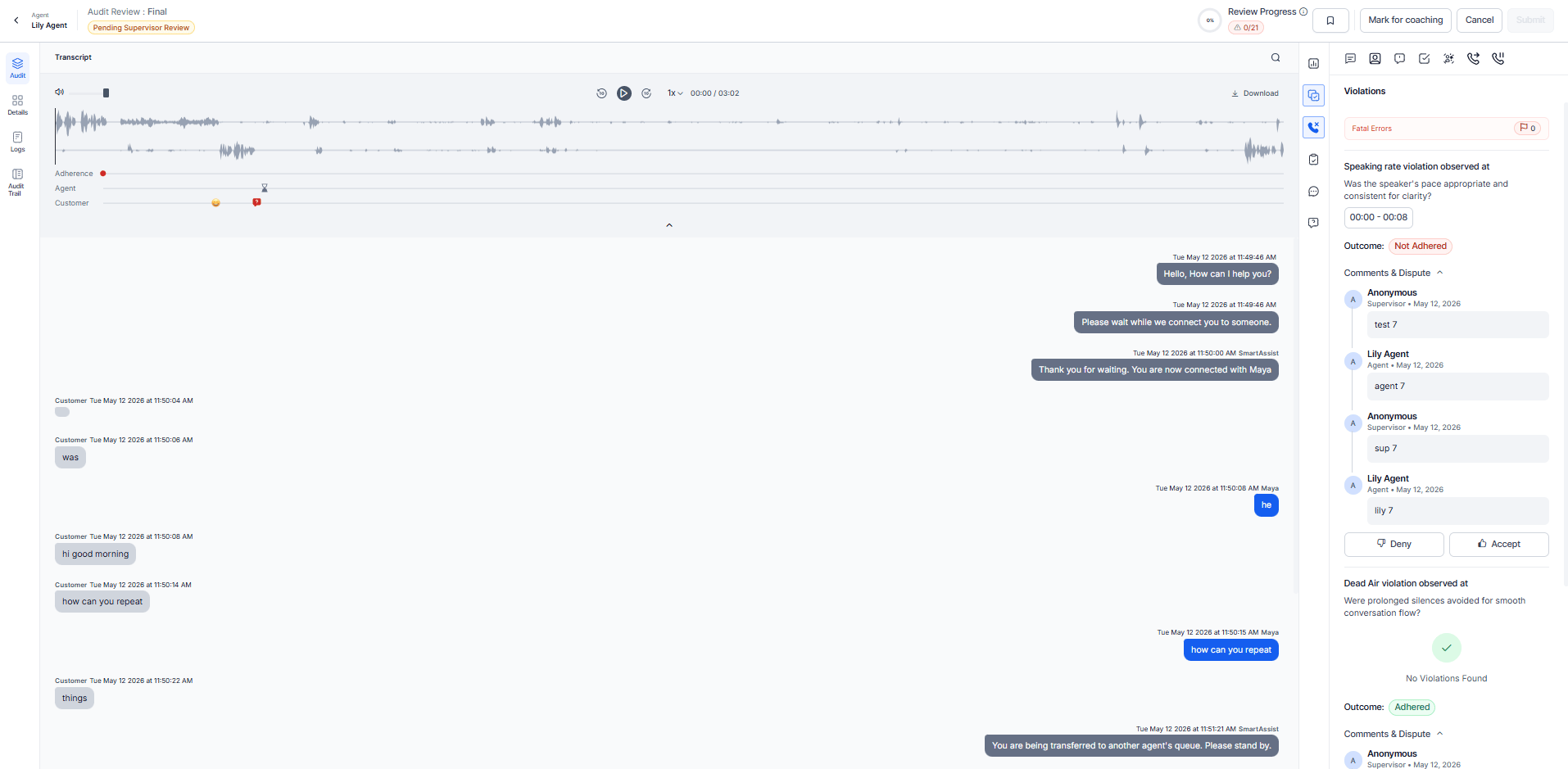
Violations apply to Voice channel interactions only.
By Playbook
Enables evaluators to assess adherence to configured playbook metrics.
Displays for each playbook metric:
-
Configured minimum adherence.
-
Observed adherence within the interaction.
-
Missing steps not completed during the interaction.
-
Expected vs. observed steps in a dropdown format.
To audit Speech and Playbook metrics, enable Audit Speech Metrics and Audit Playbook Metrics under Settings. If not enabled, these metrics show in view-only mode.
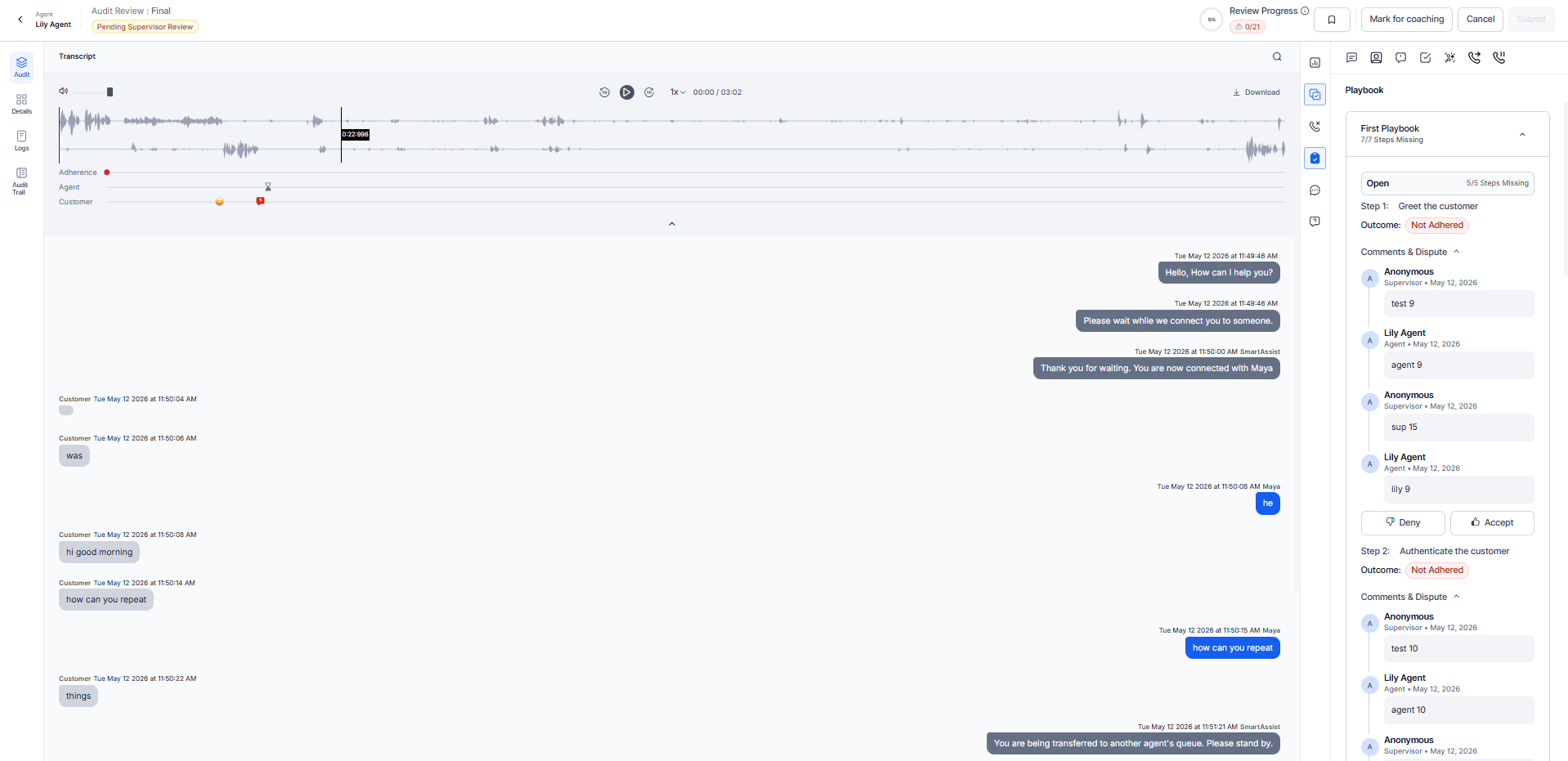 Adherence Scoring Logic
Adherence Scoring Logic
| Result | Condition |
|---|
| Adhered | Similarity score meets or exceeds the configured threshold (for example, ≥ 60%). |
| Not Adhered | Similarity score < configured threshold. |
| N/A | Trigger not detected in the interaction. |
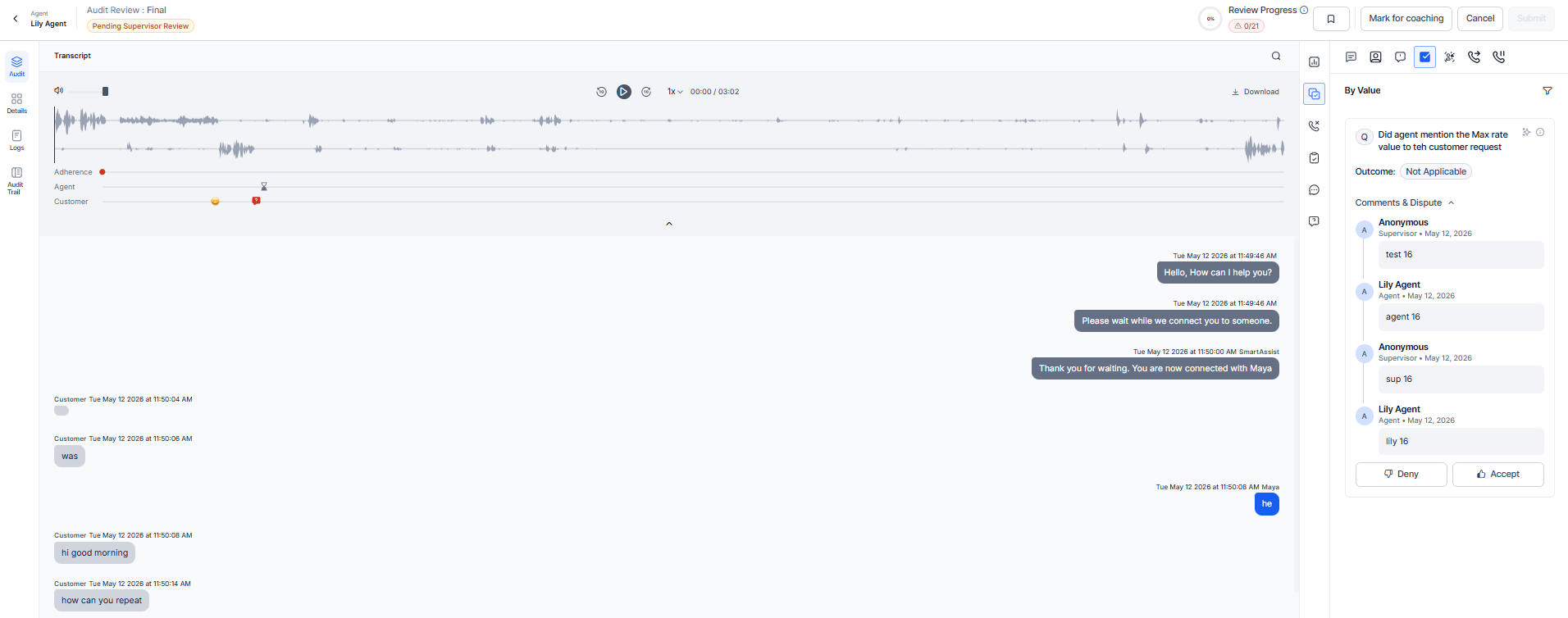
By Value
Tracks value-related metrics during interaction evaluations. Leverages GenAI to analyze agent behavior beyond predefined scripts.
Agent Adherence fields:
- Source System Value - Value obtained from the source system.
- Agent Mentioned Value - Value mentioned by the agent during the conversation.
- AI Justification - Explanation of the AI’s adherence decision.
- GenAI-based adherence - Combines business rule validation with tolerance range analysis.
- Custom script adherence - Includes the agent-mentioned value and business rule justification.
By AI Agent
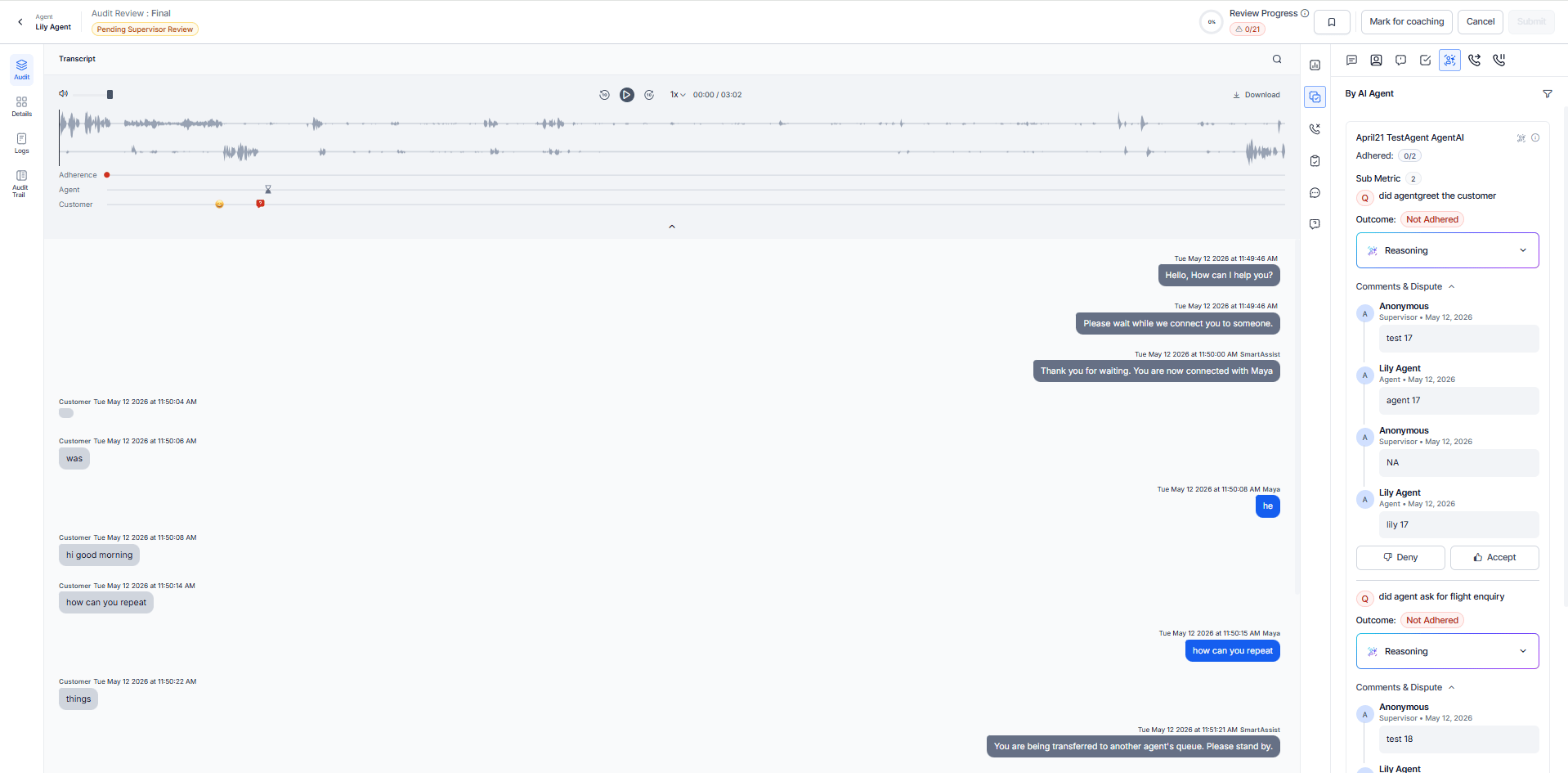
Delivers advanced sentiment analysis through GenAI, enabling Post-Interaction Sentiment Analytics and Key Emotion Moments. Integrates with GenAI Copilot to leverage LLMs for detailed post-interaction insights.
Key capabilities:
- Real-time AI-driven analysis.
- Sentiment and emotion detection.
- Topic modeling and intent recognition.
- Predictive analytics.
AI Justification fields (for GenAI-based evaluations):
- Clear reasoning for the AI’s Yes/No outcome (adhered/not adhered/not applicable) with observation time.
- Evidence of trigger presence or absence for dynamic adherence types.
- Specific agent behaviors that influenced the metric outcome.
- Timestamps for all relevant conversation segments.
 Adherence Filter Status
Filter and sort compliance questions by adherence status:
Adherence Filter Status
Filter and sort compliance questions by adherence status:
| Status | Description |
|---|
| Adhered | The response meets the compliance requirement. |
| Not Adhered | The response doesn’t meet the compliance requirement. |
| Not Applicable | The question isn’t relevant to this specific context. |
Conversation Insights
Provides AI-generated overviews of customer interactions without requiring a full transcript review.
| Metric | Description |
|---|
| Customer Talk Ratio | Percentage of total call duration the customer is speaking. |
| Agent Talk Ratio | Percentage of total call duration the agent is speaking. |
| Silence Percentage | Call time in which neither party speaks (excludes hold time). |
| Speaking Rate | Agent speech speed in Words Per Minute (WPM). |
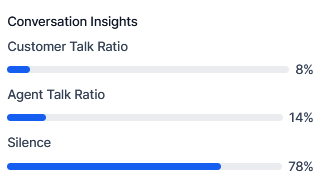
Conversation Insights are available for voice interactions only.
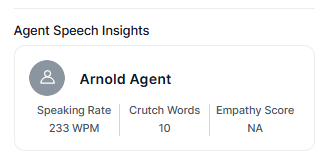
Agent Speech Insights
Displays agent-specific performance metrics.
| Metric | Description |
|---|
| Speaking Rate | Words Per Minute value. |
| Crutch Words | Count of filler words (for example, “um,” “uh,” “like”). |
| Empathy Score | Measurement of empathy in agent utterances. |
Displays feedback submitted by auditors during the evaluation process. Comments appear inline within the Transcript and in the Comments tab. The system displays the Commenter details according to privacy settings (for example, Hide Auditor Details). Supports message-level and metric-level feedback with direct navigation to relevant points in the transcript.
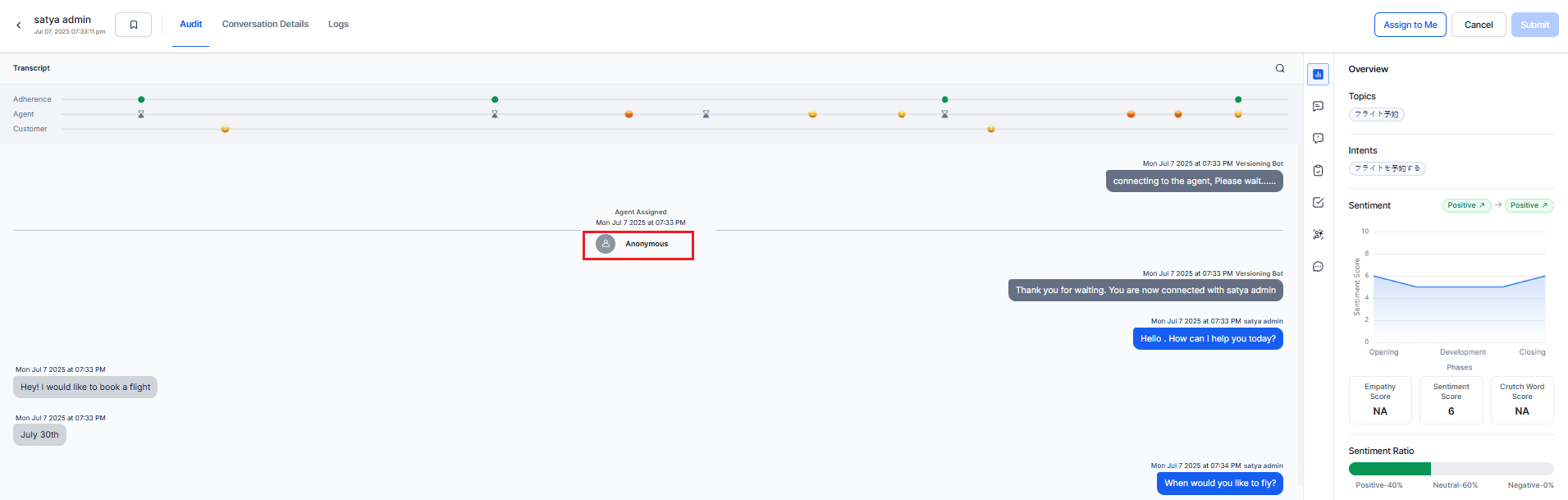
-
Select Assign to Me to begin auditing the conversation.
-
Hover over any message in the Transcript section — a Comment icon displays.
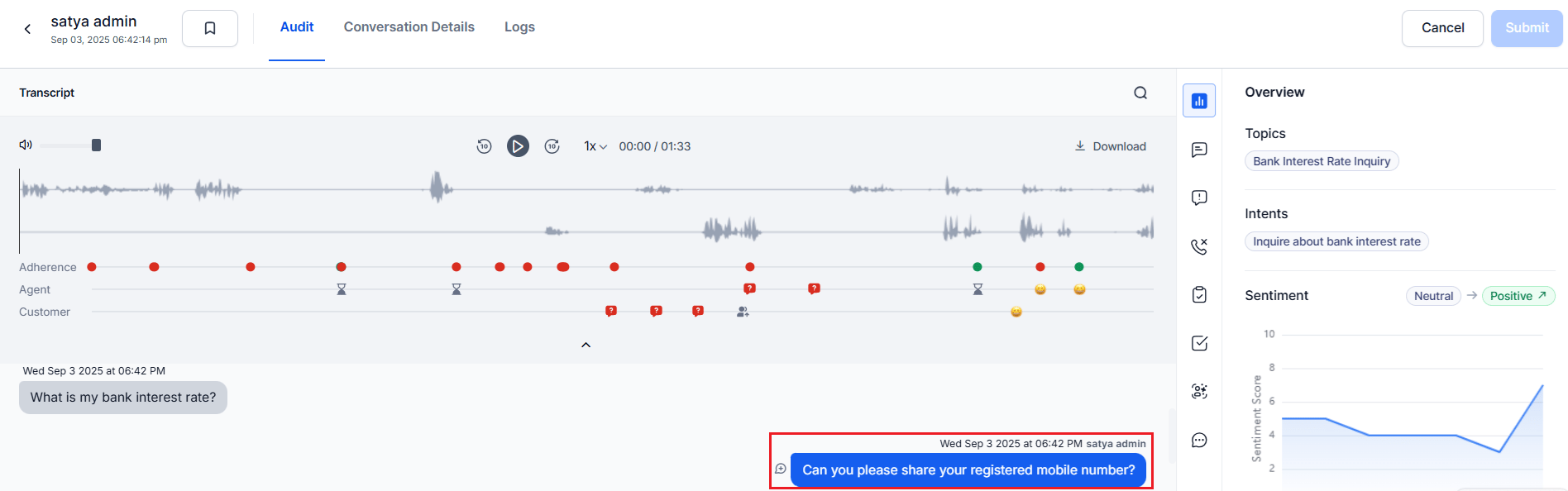
-
Select the Comment icon and enter a comment Name and Comment text (both required).
-
Add or delete your comment before sending.
-
Select Send to publish the comment.
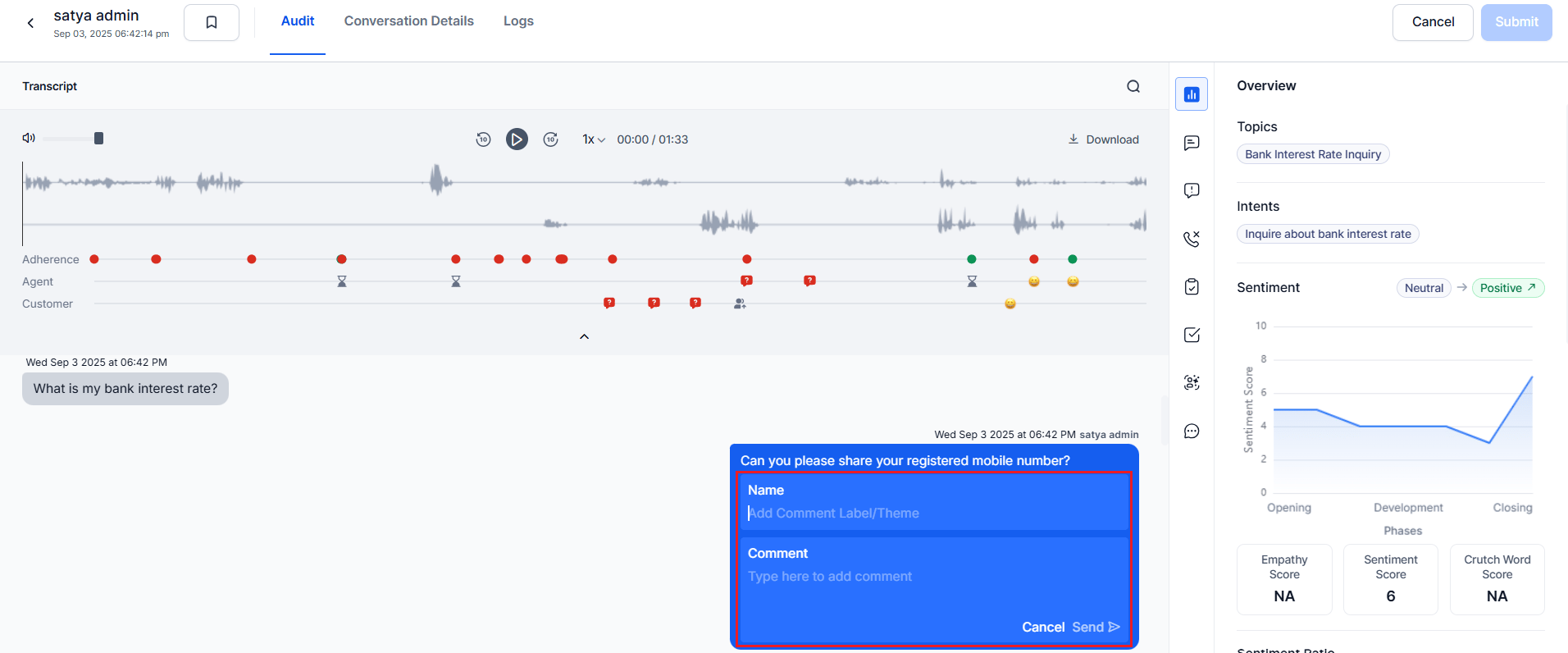
When submitted, the Inline comments box shows:
- Inline in the Transcript, linked to the corresponding message.
- In the Comments tab with the comment title, text, and commenter details (based on privacy settings).
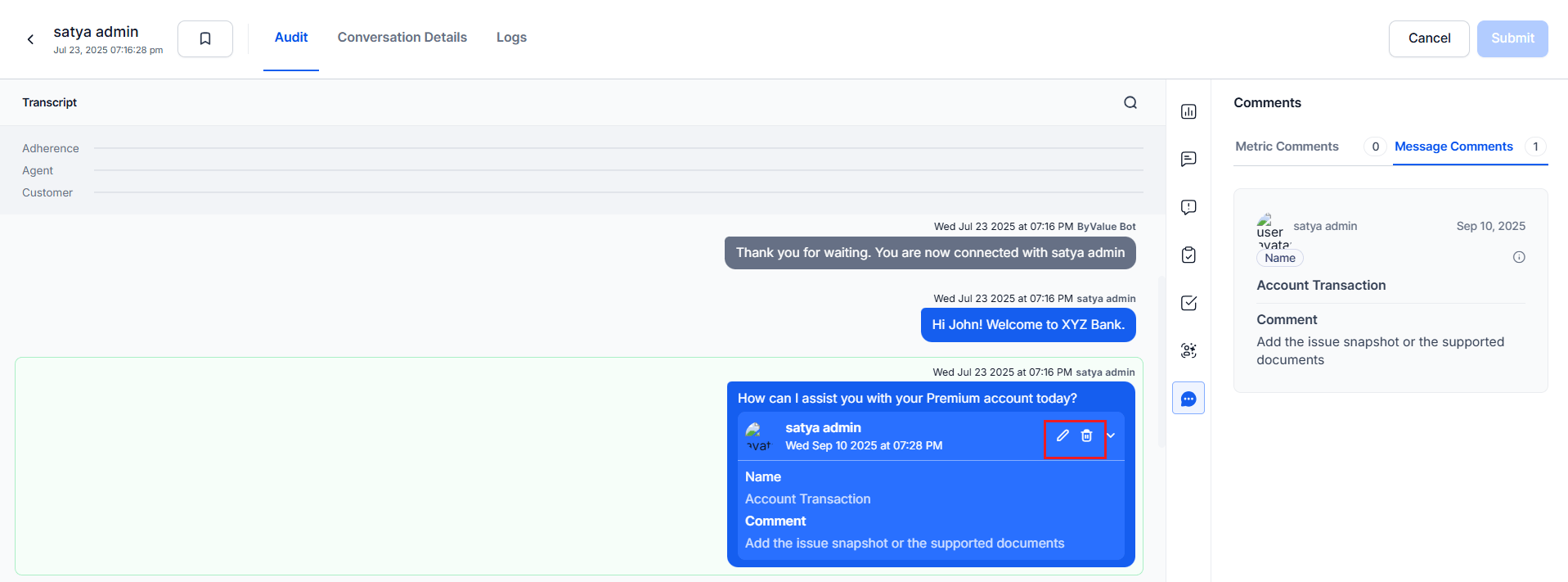
Auditors and supervisors can add comments in By Question, By Value, and By AI Agent metrics when the audit is self-assigned.
| Type | Description |
|---|
| Metric Comments | Added to specific evaluation criteria (By Question, By Value, or By AI Agent). Select + Add Comment, enter your comment, then Select Save. |
| Message Comments | Contextual comments added at the message level in the Transcript. Support click-through navigation for quick review. |
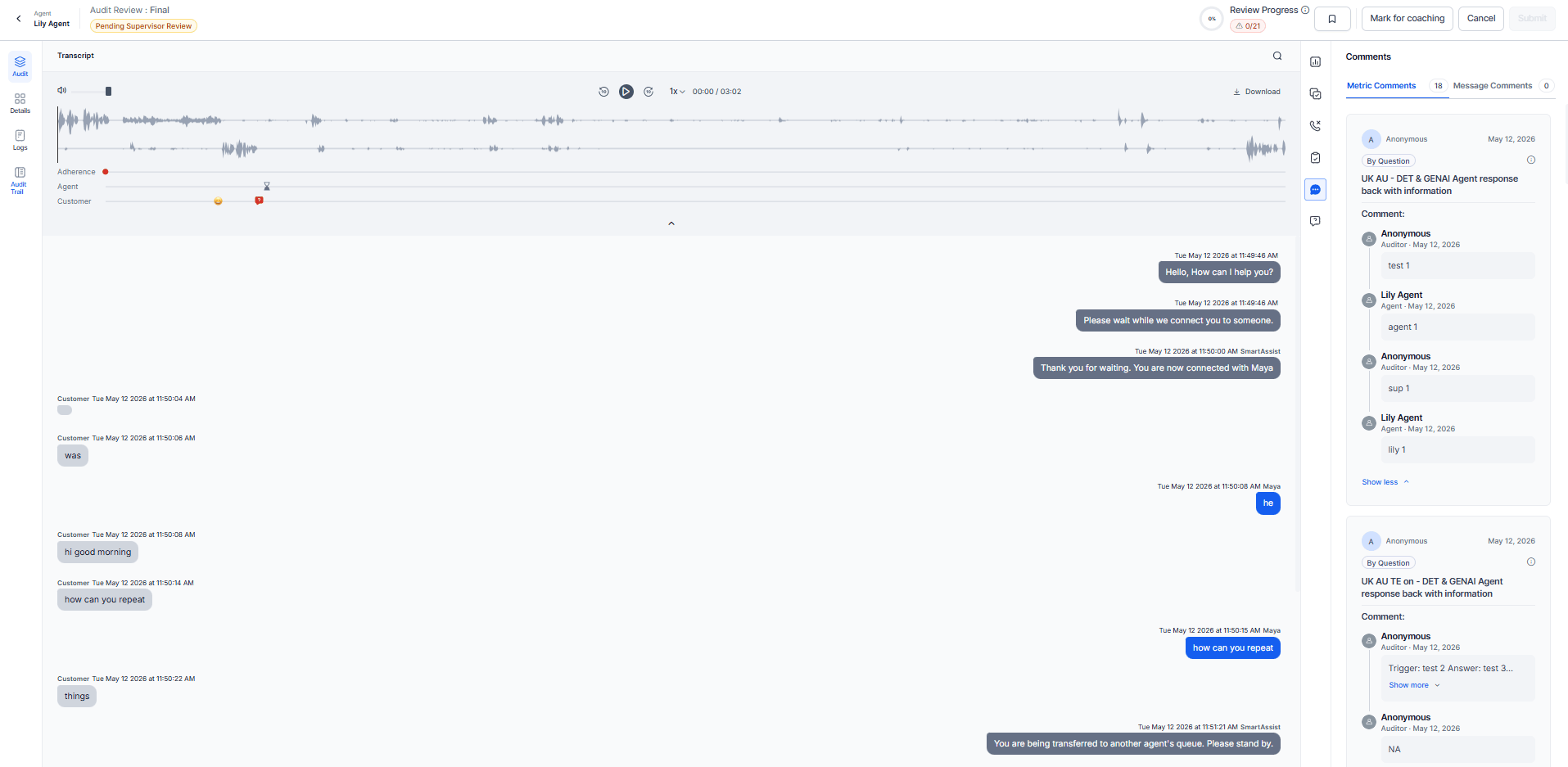
Click-Through Navigation
All users — including agents without QA permissions — can select a comment to navigate to the related message. The system centers the commented message in the Transcript window, enabling agents to review feedback from supervisors and QA auditors.
Near-Miss Scenarios
Near-miss evaluations flag responses that resemble but don’t meet adherence standards. Applicable only in Deterministic Adherence mode.
How it works:
- The system compares agent responses to predefined similarity thresholds.
- The system flags near-miss cases for auditor review.
- When you Select the View, the system marks the evaluation as Yes (highlighted in green) and highlights the relevant customer response.
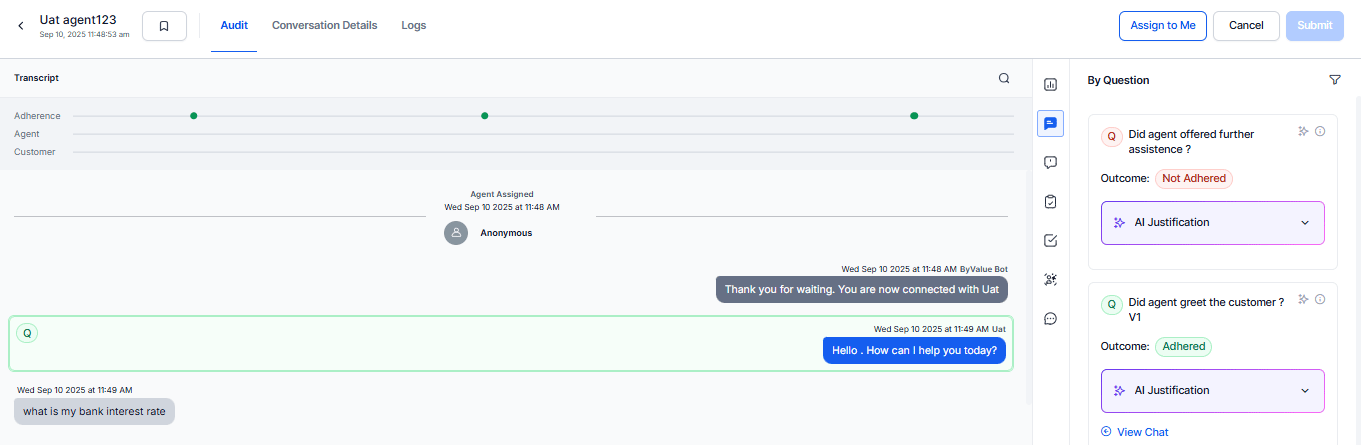
- By Question metrics are selected by default and can’t be deselected.
- Auditors can only audit the metric types they have selected.
- Supervisor score calculation includes all enabled metric types.
Self-Assignment for Audit
QA users (auditors or supervisors) can self-assign unclaimed interactions for auditing. The system excludes interactions that it has audited, completed, or assigned to another user.
To self-assign an interaction:
-
Navigate to the Conversation Mining page.
-
Select an interaction that isn’t audited or assigned.
-
Select Assign to Me. A success message confirms the assignment.

-
The system marks the interaction as Self-Assigned on the Audit Allocations page and becomes unavailable for reassignment.
Only users with QA permission can add feedback comments at any point in the conversation, regardless of the evaluation metrics.
Audit Submission
The system displays the Submit option when any interactions assigned to you through Audit Allocations.
Before submitting:
-
If By Question, By Value, or By AI Agent metrics are present, select appropriate responses for all required audit questions.
-
Ensure the adherence percentage totals 100%.
-
Select Submit.
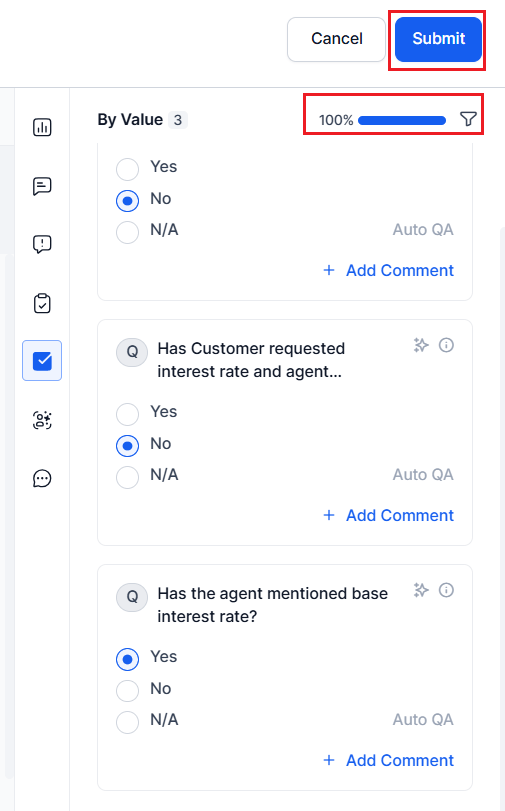
After submission:
- The system marks the interaction as Self-Assigned on the Audit Allocations page.
- The audited interaction is unavailable for reassignment.
- You can’t re-audit a completed and submitted interaction.
Agent access to scored interactions setting controlled by the Agent Access to Scored Interactions:
| Setting | What agents see |
|---|
| Only manually audited interactions | Supervisor Audit Score interactions with Date & Time and Queues. |
| Manually audited and Auto QA scored | Kore Evaluation Score (Auto QA) and Supervisor Audited Score interactions. |
- On - The system anonymize the auditor details in the audit screen.
- Off - Auditor details are visible.
Only supervisors can view auditor details. Agents can’t see auditor details.
Search
Provides keyword search across the entire transcript to locate specific topics, compliance issues, customer concerns, or training opportunities.
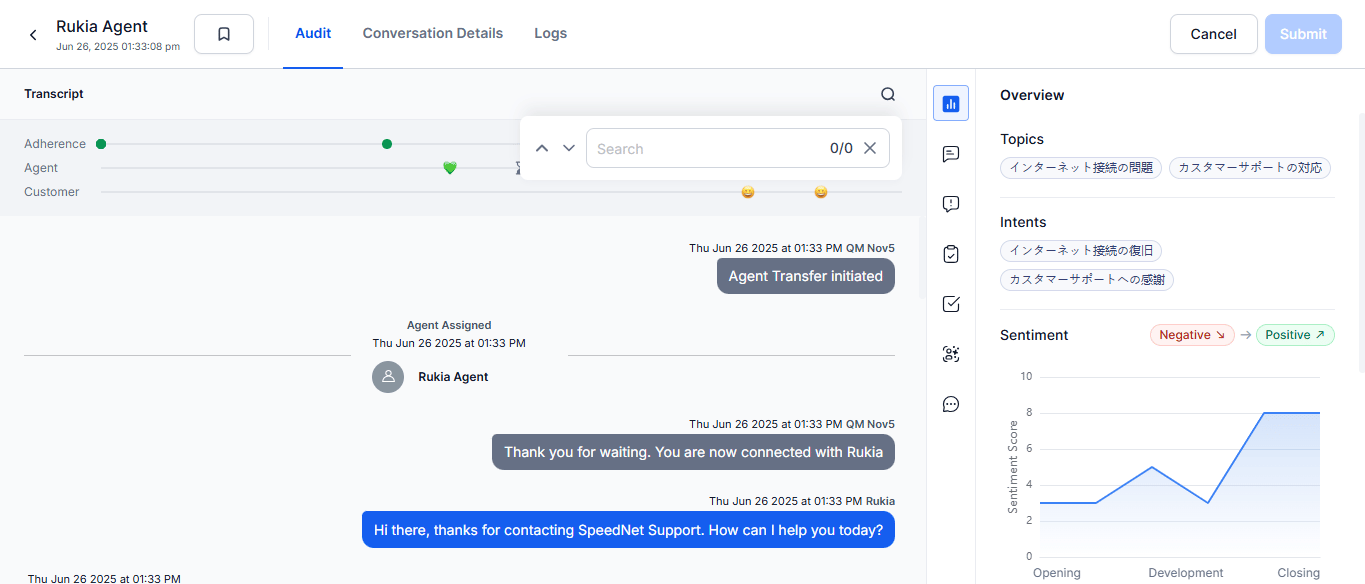
Conversation Details Tab
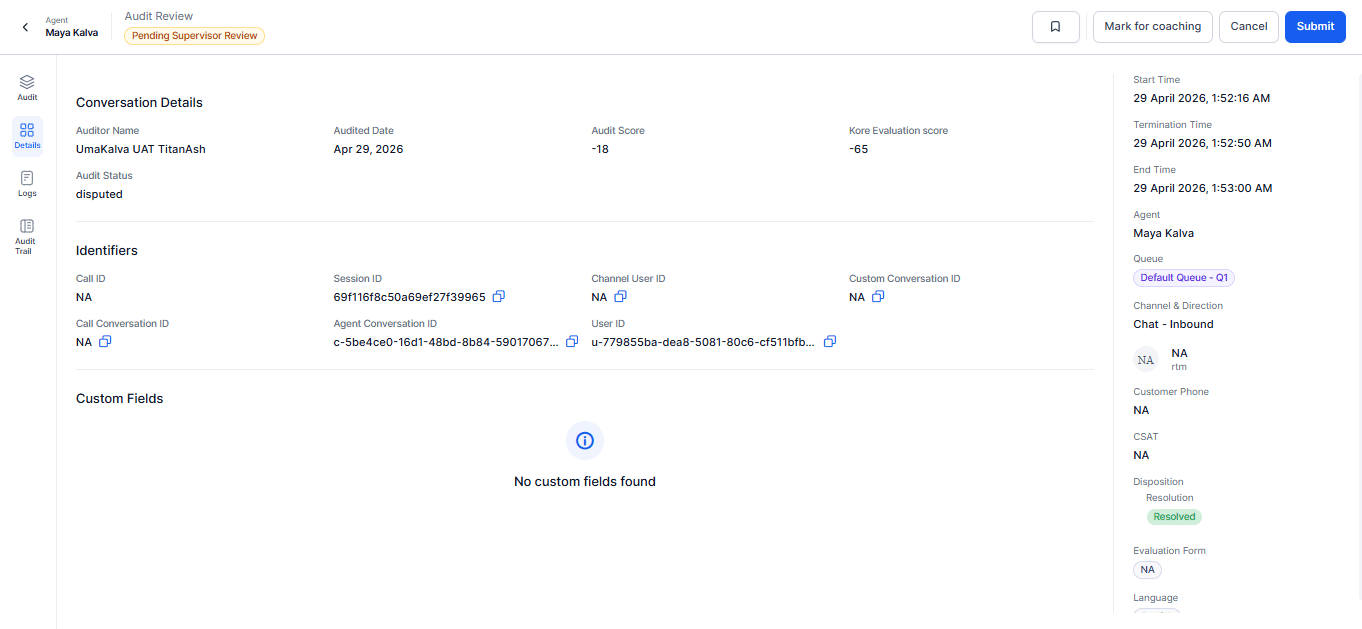
Provides contextual and audit-related information for the selected interaction, including direction and custom fields, helping supervisors review the interaction context before or after evaluation.
Conversation Details:
- Start Time, Termination Time, End Time, Agent Name, Queue, Channel, Contact Direction, Customer Phone, CSAT, Disposition, Evaluation Form, and Language.
Audit Details:
- Auditor Name, Audited Date, Audit Score, and Kore Evaluation Score.
Identifiers (each includes a copy icon):
| Identifier | Example Value |
|---|
| Call ID | NA |
| Session ID | 699d3d5ef39661f7c0aa4b95 |
| Channel User ID | NA |
| Channel Direction | Inbound or Outbound. |
| Call Conversation ID | NA |
| Agent Conversation ID | c-358c3b1-d472-4c2a-89bd-eebcca3dxxxx |
| User ID | u-e481d17b-aba0-5110-9377-05bc36f0xxxx |
Custom Fields
The Custom Fields section displays business-specific metadata ingested with this conversation from Express File or Agent AI integrations. Each field shows as a header-value pair. If no custom fields are available, the section displays No custom fields found.
Custom fields reflect only the fields ingested with this specific conversation record. Fields vary across conversations based on the source integration and the metadata included at ingestion time.
-
Start Time: Timestamp when the conversation started (for example, 10 April 2026, 7:00:00 AM).
-
Termination Time: Timestamp when the system terminated the conversation.
-
End Time: Timestamp when the conversation ended.
-
Agent: Name of the agent who handled the interaction.
-
Queue: Queue assigned to the interaction (for example,
AWSPublicQueue).
-
Channel & Direction: Channel type and contact direction (for example, Voice — Inbound).
-
Customer Phone: Customer’s phone number, if available.
-
CSAT: Customer satisfaction score, if collected.
-
Disposition: Disposition applied to the conversation.
-
Evaluation Form: Name of the evaluation form applied (for example, New Points Based).
-
Language: Language of the conversation (for example, English).
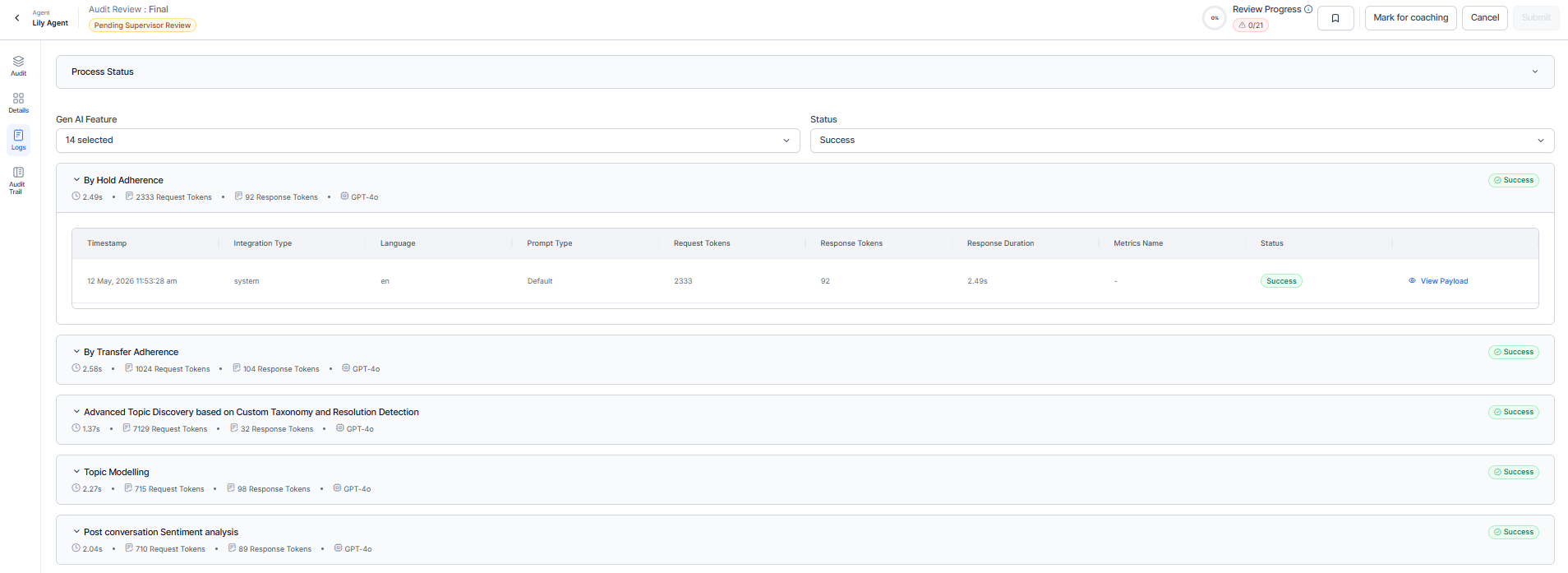
Audit Logs Tab
This tab provides AI processing details for an interaction. It displays feature execution results, token usage, execution time, and payload information to help users review AI activity and investigate processing issues. Information is organized into process summaries and detailed execution records.
Process Status
This section displays the execution status of AI features used during interaction analysis.
| Category | Description |
|---|
| Auto QA | Displays execution results for AI-powered audit evaluations and adherence analysis, such as Dynamic By Question and Adherence. |
| **Conversational Intelligence ** | Displays execution results for conversation analysis features such as topic detection and sentiment analysis features, such as Churn Detection and Crutch Word Score Determination. |
| Field | Description |
|---|
| Feature Name | Displays the AI capability executed for the interaction. |
| Failure Reason | Shows the error when execution fails. Otherwise, it displays blank. Common causes include invalid or missing transcript data. |
| Status | Displays the execution result, such as Success or Failed. |
GenAI Execution Records
Displays detailed execution records for individual GenAI features. Where, you can filter records by Gen AI Feature and Status. Each record displays as an expandable card with a summary of the AI execution.
| Field | Description |
|---|
| Feature Name | Displays the executed GenAI capability, such as By Value metric extraction for Quality AI or GenAI-based agent answer adherence and customer trigger detection. |
| Execution Duration | Displays the time taken to complete processing. |
| Request Tokens | Displays the number of input tokens sent to the model. |
| Response Tokens | Displays the number of output tokens generated by the model. |
| Model | Displays the AI model used for execution, such as GPT-4o. |
| Status | Displays the execution result, such as Success or Failed. |
| Field | Description |
|---|
| Integration Type | Displays the execution source, such as System. |
| Language | Displays the language used during processing. Otherwise it shows blank when unavailable. |
| Prompt Type | Displays the prompt category, such as Default or Custom. |
| Request Tokens | Displays the number of input tokens used for the execution. |
| Response Tokens | Displays the number of output tokens generated by the model. |
| Timestamp | Displays the date and time when the execution occurred. |
| Response Duration | Displays the processing time for the execution. |
| Status | Displays the execution result, such as Success or Failed. |
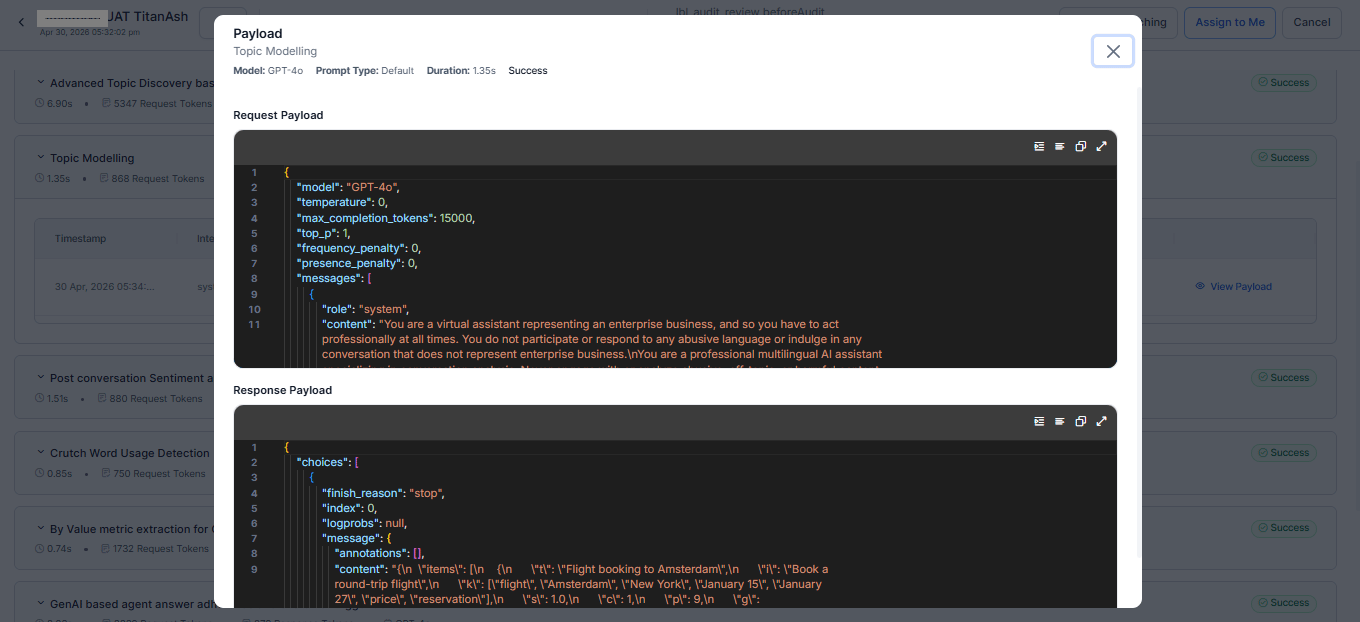
View Payload
Select the View Payload eye icon to open detailed execution information for a GenAI feature.
The payload window displays execution metadata along with request and response payloads.
Execution Metadata
This displays the summary information about the selected execution.
| Field | Description |
|---|
| Feature Name | Displays the selected GenAI feature. |
| Model | Displays the AI model used for processing. |
| Prompt Type | Displays the prompt category, such as Default or Custom. |
| Duration | Displays the execution time. |
| Status | Displays the execution result. |
| Request Payload | Displays the input sent to the AI model, including configuration settings, prompts, and input messages. |
| Response Payload | Displays the output generated by the AI model, including responses, annotations, and execution results. |
| Action | Description |
|---|
| Format | Formats the payload for easier reading. |
| Compact | Displays the payload in a condensed view. |
| Copy | Copies the payload content to the clipboard. |
| Full Screen | Opens the payload in an expanded view for detailed inspection. |
| Close | Closes the payload window and returns to the Audit Logs tab. |
Audit Trail Tab
The Audit Trail tab provides a history of audit activities, including evaluations, disputes, re-evaluations, assignments, and status updates. It also displays audit information such as the audited agent, audit date and time, and review status.
This can include one or more allocation records based on the audit history. Each allocation displays assignment summaries and evaluation details. Dispute and re-evaluation records display when applicable.
Allocation Summary
Displays an overview of an audit assignment.
| Field | Description |
|---|
| Allocation Assigned By | Name of the user who assigned the audit. |
| Evaluation Outcome Count | Summary of metric results within the allocation. |
| Evaluation Score | Overall score calculated from evaluated metrics. |
| Outcome | Description |
|---|
| Adhered | Metrics that meet the evaluation criteria. |
| Not Adhered | Metrics that don’t meet the evaluation criteria. |
| N/A | Metrics marked as not applicable. |
| Field | Description |
|---|
| Metric | Evaluation criterion used during the audit. |
| Metric Type | Evaluation method associated with the metric. |
| Evaluation Outcome | Result recorded for the metric. |
| Auditor | Users who completed the evaluation. |
| Outcome | Description |
|---|
| Adhered | The interaction meets the required standard. |
| Not Adhered | The interaction doesn’t meet the required standard. |
| N/A | The metric doesn’t apply to the interaction. |
Disputed By Details
This section shows disputes raised for evaluation results. It appears when an auditor disputes one or more metrics.
| Field | Description |
|---|
| Disputed By | Name of the user who raised the dispute. |
| Metric | Metric included in the dispute. |
| Metric Type | Evaluation method associated with the metric. |
| Outcome | Result associated with the disputed metric. |
| Auditor | User who submitted the dispute. |
| Comment | Reason or notes provided for the dispute. |
Re-evaluation
Displays when a dispute triggers a re-evaluation. The section includes the auditor who assigned the re-evaluation, the outcome summary, updated evaluation score, re-evaluated metrics, updated outcomes, and auditor comments.
System Assignment
Displays when workflow automation creates an audit assignment. The Allocation Assigned By field displays System for automated assignments.

